Καλωσήλθατε στο πρώτο Portal ΥΓΕΙΑΣ που σχεδιάστηκε και λειτουργεί με Τεχνητή Νοημοσύνη
To IRIBEYOND είναι μια ερευνητική πρωτοβουλία, ως αποτέλεσμα συνεργασίας του Ινστιτούτου Έρευνας και Καινοτομίας και του Εργαστηρίου Μοριακής Βιολογίας και Ανοσολογίας του Τμήματος Φαρμακευτικής του Πανεπιστημίου Πατρών.
Προσοχή, τα δεδομένα της Τεχνητής νοημοσύνης είναι ακόμα σε BETA στάδιο εκμάθησης, Όλες οι ερωτήσεις που κάνετε καταγράφονται από την ομάδα μας για την καλύτερη εκπαίδευση της. Η υπηρεσία φωνής και διαλόγου θα χρειαστεί πρόσβαση στο μικρόφωνό σας.
Η παρούσα εφαρμογή είναι ερευνητική προσπάθεια. Για συμβουλές φαρμάκων και συμπληρωμάτων διατροφής παρακαλώ ρωτήστε τον θεράποντα ιατρό και τον φαρμακοποιό σας. Μπορείτε να ρωτήσετε για οτιδήποτε την Τεχνητή Νοημοσύνη Ιπποκράτης και με το μικρόφωνό σας.
Τo IRI Beyond δίνει ιδιαίτερη έμφαση σε τεχνολογίες αιχμής στον χώρο της Υγείας και της Ευεξίας.
Τουτο αποτελεί μια ανοικτή σε συνέργειες «πλατφόρμα δράσεων και πρωτοβουλιών» που συνεχώς εξελίσσεται παρακολουθώντας από κοντά τις επιστημονικές, τεχνολογικές, οικονομικές και κοινωνικές εξελίξεις στην Ελλάδα και διεθνώς.
Chatbot Τεχνητής ΝοημοσύνηςΡωτήστε τον “Ιπποκράτη”απαντάει άμεσα σε ζητήματα υγείας & ευεξίας και όχι μόνο!
Το 2024, σου έχουμε ευχάριστα νέα:Εγκαταστήσαμε στο Ηλεκτρονικό μας Κατάστημα Yperikon.gr, τον αυτόματο προσωπικό βοηθό (chatbot) Τεχνητής Νοημοσύνης «Ιπποκράτη». Θα τον δείτε να εμφανίζεται κάτω αριστερά, σε κάθε σελίδα. ως ένα πράσινο κουμπί που αναγράφει «IRI AI – Ρωτήστε τον Ιπποκράτη».
Τι κάνει το AI chatbot “Ιπποκράτης”; Ο «Ιπποκράτης» απαντάει στα ερωτήματα που θα του θέσετε, με μία εξειδίκευση στα ζητήματα υγείας και ευεξίας.
Πως μπορώ να το χρησιμοποιήσω; Κάντε τις ερωτήσεις που θέλετε συμπληρώνοντας το πεδίο (ή φωνητικά με το μικρόφωνο σας) και θα λάβετε τις εξατομικευμένες απαντήσεις και την καθοδήγηση σχετικά με τις ανάγκες σας. Ο «Ιπποκράτης» θα ανταποκριθεί στις απορίες σας όλο το 24ωρο, δηλαδή και τις ώρες που η ομάδα των συνεργατών μας δεν θα είναι διαθέσιμη να σας απαντήσει τηλεφωνικά ή μέσω μηνυμάτων.
Σε αυτό το σημείο να καταστήσουμε σαφές πως σε ότι μας αφορά, δεν θεωρούμε τις υπηρεσίες Τεχνητής Νοημοσύνης πανάκεια αλλά τις προσεγγίζουμε ως ένα τεχνολογικό εργαλείο που έχει να μας προσφέρει κάτι χρήσιμο μεν αλλά που δεν είναι σε θέση να αντικαταστήσει (ούτε θα το θέλαμε) τηνανθρώπινη σχέση δηλαδή την πνευματική και ψυχική αλληλεπίδραση μεταξύ μας. Επίσης τις απαντήσεις που θα λάβετε χρησιμοποιήστε τις ως βοήθημα για την περαιτέρω έρευνα σας σχετικά με τα ζητήματα υγείας και ευεξίας που σας απασχολούν.
Έχοντας ξεκαθαρίσει αυτό το σημαντικό και λεπτό σημείο, μπορείτε να ξεκινήσετε να χρησιμοποιείτε τον “ Ιπποκράτη” κάνοντας του ερωτήσεις όπως:
“ τι μπορώ να σε ρωτήσω Ιπποκράτη; “ “ τι βότανα συστήνονται στον πονόλαιμο; “ “ πόσα αποξηραμένα μύρτιλλα μπορώ να τρώω την ημέρα ; “ “ με ποια φάρμακα αντενδείκνυται η λήψη cbd ; “ “ υπάρχουν πιθανές παρενέργειες από την κατανάλωση κουρκουμά ; “
Ελπίζουμε ότι η νέα υπηρεσία μας, που διατίθεται δωρεάν από την εταιρεία μας ως αντίδωρο για την προτίμηση που μας δείχνετε, θα σας ενθουσιάσει με τις αμέτρητες δυνατότητες της που θα βελτιώνονται συνεχώς όσο θα «εκπαιδεύετε» το AI Chatbot με τις ερωτήσεις σας!
Πείτε μας την γνώμη σας ή την εμπειρία σας όποτε θελήσετε!
USE OF CLOUD COMPUTING – CURRENT SITUATION AND FRAMEWORK SCENARIO Current situation Cloud computing is changing the way IT is used. While in the 2000s the operation of IT hardware and software (“on premise”) was still the norm for companies and other organizations, cloud services are increasingly becoming the dominant form of IT use in the current decade. Advantages such as flexibility, scalability, lower administration costs or no investment costs mean that more and more organizations are opting to use cloud services. Cloud services are also becoming increasingly popular in the private sector – often in the form of free offers or as a flat rate service. The trend towards more cloud computing is also having a positive effect on the economy as a whole, as confirmed by a study conducted by IDC on behalf of the European Commission – DG Communications Networks (IDC, 2015). In the baseline scenario, the GDP in the EU is expected to rise by €103 billion by 2020. That corresponds to 0.71% of the GDP. This economic growth would be linked to over 300,000 new businesses and almost 1.6 million new jobs in the EU (IDC, 2015) (Figure 1).
For the above mentioned IDC study, a total of 1651 companies with 10 or more employees, in France, German, Italy, Spain and the UK, were interviewed during October 2013. About 70% of these companies used at least one public cloud service in 2015; 48% used a private cloud service. This means that the number of cloud users in the IDC survey is significantly higher than the number of cloud users in the EU calculated by Eurostat2 . According to Eurostat, a total of 26% of the enterprises in the EU28 use cloud services; 18% use public cloud services and 11% private cloud services. Cloud use by enterprises is particularly high in Finland, Sweden and Denmark, while relatively few cloud services are used in Poland, Romania and Bulgaria (Figure 2). For the Eurostat survey, 158,000 enterprises with more than 10 employees were surveyed in all EU28 countries (Eurostat, 2018). There are only assumptions as to how the deviations in the results of the IDC survey from the Eurostat survey can be explained. It could be that IDC surveyed more of the relatively large companies. According to the Eurostat survey, 56% of the large enterprises use cloud
services, while only 25% of the small and medium-sized enterprises use cloud services. It
is also possible that IDC, a company active in ICT market research, has increasingly
reached ICT savvy companies in its survey, companies that use more cloud services than
the average business.
Figure 1 – EU: New GDP, companies and employment from the Cloud (Source IDC 2014)
Irrespective of the current level of the percentage of cloud users, both IDC and Eurostat conclude that the use of cloud services in enterprises is increasing significantly and that cloud use is becoming the mainstream in the EU (Eurostat, 2018; IDC, 2015). This trend is also confirmed by further studies on European markets, e.g. by Cisco (Cisco, 2018a), Bitkom/KPMG (KPMG & Bitkom, 2018b), the Dutch Data Centre Association (Dutch Data Centre Association, 2017), the Cloud Industry Forum (CIF, 2017). The use of cloud services is also increasing in the private sector. In the EU28 countries, 56% of individuals aged 16 to 74 used the internet for social networking in 2018 (Eurostat, 2019). In the United Kingdom, Sweden, Belgium and Denmark 70 to 80% of individuals use social networks. In the three EU Member States Slovenia France and Italy, the use of social media is under 50% ( Figure 3). According to Cisco, consumer applications are responsible for about 25% of workloads and compute instances in data centres worldwide. Of these, the cloud applications search, social networking and video streaming account for about 2/3 (Cisco, 2018a). According to Cisco, the use of cloud services by enterprises and private households is already responsible for the majority of data processing, storage and transmission in data centres and networks. By 2019, nearly 90% of the workloads and compute instances3 in data centres in Western Europe will be cloud workloads and only 10% traditional workloads. Measured in terms of the number of servers, this means that 70% of servers in Western Europe are operated as cloud servers. Measured by data centre IP traffic, cloud computing will be responsible for 93% of the traffic in Western Europe in 2019 (Cisco, 2018a).
Figure 2 – Use of cloud computing services in enterprises (Eurostat, 2018)
Figure 3 -Individuals who used the internet for participation in social networking, 2017 (Source: Eurostat 2018)
Cisco also provides information on how the workloads and compute instances of the cloud data centres are divided between private and public cloud services. According to these figures, around 30% of the world’s cloud workloads and compute instances will be private by 2019 and 70% will be public cloud workloads and compute instances. The trend towards more public cloud services is accompanied by an increase in the number of cloud hyperscale data centres. Cisco has identified 24 cloud companies that generate billions of dollars in revenue from cloud services. The data centres operated by these companies are considered hyperscale data centres. Cisco expects the number of these data centres worldwide to increase from 338 to 628 between 2016 and 2021.According to Cisco, 53% of all data centre servers will be operated in hyperscale data centres by 2021 and 55% of data centre IP traffic will be caused by hyperscale data centres (Cisco, 2018a). The United States Data Centre Energy Usage Report assumes somewhat more conservatively that by 2020 about 40% of servers in the USA will be operated in hyperscale data centres (Shehabi et al., 2016).
Figure 4 – Deployed global cloud services from 2016 to 2021 (Source: Cisco 2018)
If one distinguishes between the provisioning models IaaS, PaaS and SaaS, SaaS dominates in cloud services. According to Cisco, SaaS accounts for over 70% of workloads and compute instances in cloud data centres (Figure 4). This dominance of SaaS as a delivery model is confirmed by IDC’s Smart 2013 study, according to which the SaaS market in the EU with a volume of € 8,477 million will account for around 75% of the total market for cloud services in 2015 (IDC, 2015). According to Eurostat (Eurostat, 2018), companies use e-mail, storage of files and office software (Figure 5) particularly frequently as cloud services. According to IDC’s Smart 2013 study, cloud services are particularly common in office collaboration; 20.1% of the companies surveyed use or plan to use cloud services. Other frequent areas of application include customer relationship management (CRM) (17%), storage (16.4%), database as a service (16.2%), security (15.4%), unified communications (15.2%) and enterprise resource planning (ERP) (14.8%) (IDC, 2015).
Figure 5 – Use of cloud computing services in enterprises, by purpose, 2014, 2016 and 2018 (% of enterprises using the cloud) (Source: Eurostat 2018)
In terms of industries, companies from the finance, telecommunications, media and distribution sectors in the EU make above-average use of public cloud services (Figure 6). The use of cloud services in the manufacturing sector is below average. Healthcare/education companies frequently use private cloud services (IDC, 2015).
Figure 6 – Use of cloud computing by industries in 2015 (Source: IDC 2015)
Estimation of energy consumption of cloud computing The significant increase in the use of cloud services is also leading to an increase in the energy consumption of cloud computing. However, it is very difficult to quantify exactly how much energy is needed for cloud computing. This is due to the fact that it is difficult to distinguish energy requirements from cloud services and other – traditional – services running on ICT infrastructures (Prakash et al., 2014). Determining the energy demand of cloud computing also depends on how cloud services are precisely defined. There are some studies that deal with the energy needs of cloud computing, but there is little information on how much energy cloud services require overall in data centres and networks. For example, there is a study by the Centre for Energy-Efficient Telecommunication on the energy demand of wireless cloud solutions (CEET, 2013). This study comes to the conclusion that for wireless cloud solutions 90% of the energy required arises in wireless networks and only 9% in data centres. In a case study for the USA, Masanet et al., identify energy-saving
potentials through the use of cloud services. The authors estimate a technical savings potential of 87% in energy consumption if typical office applications are shifted to the cloud (Masanet et al., 2014). In some studies and publications, the energy demand of cloud computing is simply equated with the energy demand of the entire internet (Cook, 2012; Cook et al., 2014; Hintemann & Clausen, 2016; Mills, 2013). Such an analysis provides at least an overview of the impact of cloud computing on energy demand, as cloud workloads and cloud traffic – as shown above – account for a high proportion of the overall performance of the internet. In addition, the current growth of IT infrastructures is mainly due to the growth of cloud services (Hintemann, 2018; Shehabi et al., 2016). Several scientific studies examine the current energy consumption of data centres and networks. In the following, the results of some studies dealing with the energy requirements of data centres and network infrastructures are presented in a short overview. Energy consumption of data centres worldwide A study on the development of the energy demand of ICT solutions comes from Andrae und Edler (Andrae/Edler, 2015). The results of this paper have received a relatively high level of attention in the discussion about the energy consumption of data centres (Belkhir & Elmeligi, 2018; Jones, 2018; Malmodin & Lundén, 2016, 2018; Pohl & Finkbeiner, 2017). This is certainly due to the fact that Andrae/Edler forecast a strong increase in energy consumption, especially in the next decade. According to their calculations, data centres worldwide will need around 480 terawatt hours per year (TWh/a) in the expected scenario in 2018. Figure 7 shows the results of various current studies on the development of the energy demand of data centres worldwide in the years 2010 to 2018. As the figure shows, it is currently impossible to speak of a reliable state of knowledge on the development and level of the energy demand of data centres worldwide. According to the studies considered, the annual energy demand of data centres worldwide in 2018 was between 200 and 800 TWh/a.
Figure 7 – Overview of studies on the current energy requirements of data centres
Energy consumption of data centres in Europe In contrast to the global situation, the results of various studies on the energy consumption of data centres in Europe are much closer together. The preliminary Ecodesign study on enterprise servers and data devices identifies an energy consumption of 78 billion kWh for data centres in Europe by 2015 (Bio by Deloitte & Fraunhofer IZM, 2016). In a study on the practical application of the new framework methodology for measuring the environmental impact of ICT, Prakash et al., calculate an energy consumption in the EU27 of 52 billion kWh for 2011 and forecast an increase to 70 billion kWh by 2020 (Prakash et al., 2014). In 2018, Borderstep Institute estimated the development of the energy demand of data centres in Western Europe based on the development of workloads and server numbers. According to this estimate, energy consumption rose by a good 30% from 56 billion kWh in 2010 to 73 billion kWh in 2017 (Hintemann, 2018). Energy consumption of networks Even for the development of the energy demand of network infrastructures worldwide, it cannot be said that the available studies come to similar results. The range of results is similar to that for data centres (Figure 8). The Andrae/Edler study mentioned above calculates an annual energy demand of 600 TWh/a for fixed and mobile radio networks in
In 2019, Andrae presented an update of his own calculations in which he calculated an energy demand of only 362 TWh/a per year (Andrae, 2019b). This clear difference in the calculations carried out by one individual author is a symbol of the uncertainty currently present in the calculations. A current study for the ‘shift project’ calculates an energy demand of 478 TWh/a for the year 2017 (The Shift Project, 2019). Investigations by Malmodin/Lunden (Malmodin & Lundén, 2018) and van Heddeghem et al., (Van Heddeghem et al., 2014) arrive at energy requirements between 200 and 300 TWh/a. A rough Borderstep Institute estimation of the energy demand of network infrastructures leads to even lower energy requirements (Hintemann & Clausen, 2016). In this estimate, the energy demand of mobile and fixed networks per terminal device is determined on the basis of a study for Germany and these values are multiplied by the number of terminal devices worldwide. Since Germany is relatively well equipped with a high density of ICT devices, it seems plausible that this estimate is nearer the lower limit of the energy demand of networks worldwide.
Figure 8 – Comparison of studies on the current energy demand of network infrastructures For the EU27, Prakash et al., calculated an energy demand of 20.5 TWh/a for mobile and fixed networks in 2011 and forecast an increase to 50 TWh/a by 2020 (Prakash et al., 2014). From today’s perspective and taking into account available studies on the worldwide energy demand of telecommunications networks, it can be assumed that the current energy consumption of telecommunications networks in the EU28 is between 60 and 80 TWh/a. This is comparable to the energy consumption of data centres.
(TO BE CONTINUED)
notes
2 Other studies – such as the annual Cloud Monitor used by KPMG/Bitkom in Germany (KPMG & Bitkom, 2018b) or the annual Cloud Computing Whitepaper published by the Cloud Industry Forum in the UK (CIF, 2017) – also arrive at significantly higher cloud usage rates than the Eurostat study. While the Cloud Monitor for Germany states that 66%of companies used cloud services in 2017, Eurostat assumes that the usage rate was only 22% in 2018. CIF indicates that 88% of the companies in the UK used cloud services in 2017, while the usage rate according to Eurostat was only 41.9% in 2018.
3 Cisco defines workload and compute instance as follows: “A server workload and compute instance is defined as a virtual or physical set of computer resources, including storage, that are assigned to run a specific application or provide computing services for one to many users.” (Cisco, 2018a)
Κεφάλαιο 3° 3 Ζητήματα Ασφάλειας Ρ2Ρ δικτύων Η ασφάλεια είναι ένα ουσιαστικό συστατικό οποιουδήποτε συστήματος ηλεκτρονικών υπολογιστών, και είναι απαραίτητη για τα Ρ2Ρ συστήματα. Στα εξής τμήματα θα περιγράφουμε τα κύρια ζητήματα Ρ2Ρ ασφάλειας. 3.1 Ανάγκη για την ασφάλεια Σε αυτούς τους ταραχώδεις καιρούς θα πίστευε κανείς ότι τα P2P ζητήματα ασφάλειας θα είναι το μικρότερο από τα προβλήματά του κόσμου. Εντούτοις οι εταιρικές απάτες και η απώλεια εισοδήματος λόγω των επιθέσεων στα εσωτερικά δίκτυά τους έχουν φέρει στην πρώτη γραμμή στον κόσμο της πληροφορικής παγκοσμίως. To Napster όπως αναφέραμε ήταν το πρώτο P2P δίκτυο και παρόλο που προκάλεσε πολλές δικαστικές αποφάσεις όλο και περισσότερες εφόρμαγες δημιουργήθηκαν μετά από αυτό, με αποτέλεσμα να προκαλέσουν εταιρικούς παγκόσμιους πονοκεφάλους. Όμως με τα καλύτερα πρωτόκολλα ασφάλειας αυτός ο πονοκέφαλος θα μπορούσε να μετατραπεί σε πολύτιμο προτέρημα για τον εταιρικό κόσμο και για τον κόσμο γενικά. Το παρακάτω διάγραμμα επεξηγεί τα χάσματα στην ασφάλεια κατά χρησιμοποίηση των P2P εφαρμογών. Μπορούμε να δούμε ότι αφήνουμε αυτές τις εφαρμογές να μπουν μέσα στα δίκτυά μας. Η ασφάλεια του «ασφαλούς» δικτύου μας είναι τώρα στη διακινδύνευση.
Εξαιτίας αυτού, εμείς είμαστε αυτοί που θα πρέπει να προστατέψουμε τον εαυτό μας. Πρέπει να περιγράψουμε τα στοιχεία που είναι σημαντικά για εμάς να χρησιμοποιήσουμε, προτού αντιμετωπίσουμε το ζήτημα της ασφάλειας. Τα κύρια σημεία είναι ο έλεγχος σύνδεσης, έλεγχος προσπέλασης, έλεγχος λειτουργίας και φυσικά η προστασία των στοιχείων που αποθηκεύονται στις μηχανές μας. Η σύνδεση, η πρόσβαση, και ο έλεγχος λειτουργίας είναι τα ζητήματα προτεραιότητας εδώ. Εάν μπορούμε να καταστήσουμε αυτά ασφαλή, τα άλλα δύο σημεία προκύπτουν από αυτά.
3.2 Συνέπειες της κακής Ασφαλείας Η P2P δικτύωση επιτρέπει στο δίκτυό να είναι ανοικτό στις διάφορες μορφές επίθεσης, διάρρηξης, κατασκοπείας, και κακόβουλης αναστάτωσης, δεν φέρνει νέες απειλές στο δίκτυο, αλλά γνωστές απειλές όπως τα σκουλήκια και οι επιθέσεις ιών. Τα P2P δίκτυα μπορούν επίσης να επιτρέψουν σε έναν υπάλληλο να μεταφορτώσουν και να χρησιμοποιήσουν το υλικό με τέτοιο τρόπο που παραβιάζει τους νόμους πνευματικής ιδιοκτησίας, και να μοιραστούν τα αρχεία με έναν τρόπο που παραβιάζει τις πολιτικές ασφαλείας οργανώσεων. Οι εφαρμογές όπως Napster, Kazaa, Grokster και άλλες είναι αρκετά δημοφιλείς στους χρήστες του internet, λόγω ότι οι χρήστες μπορούν να μεταφέρουν μεταξύ τους μουσική αλλα και αλλα αρχεία. Έτσι πολλοί χρήστες εκμεταλλεύονται τους εργοδότες τους που έχουν μεγάλες συνδέσεις για να μεταφορτώνουν αρχεία στην εργασία. Αυτό παρουσιάζει τα 14πολυάριθμα προβλήματα για το εταιρικό δίκτυο όπως η χρησιμοποίηση του ακριβού εύρους ζώνης και την προσβολή από ιούς, μια επίθεση μέσω ενός μολυσμένου αρχείου μεταφορτωμένου. Κλοπή: Το πρόβλημα με τα P2P δίκτυα κοινής χρήσης αρχείων είναι ότι αθελά μας μπορούμε να μοιραστούμε πάρα πολύ περισσότερο από ό, τι νομίζουμε ότι μοιραζόμαστε. Με το ανέβασμα και το κατέβασμα υλικού που προστατεύεται από πνευματικά δικαιώματα σε δίκτυα Ρ2Ρδεν παραβιάζετε μόνο ο νόμος, αλλα και εκθέτουμε ενδεχομένως τον υπολογιστή ,προσωπικές πληροφορίες αλλα και άλλες ευαίσθητες πληροφορίες, όπως τα τραπεζικά στοιχεία και αριθμούς κοινωνικής ασφάλισης. Με αποτέλεσμα σημαντικές πληροφορίες να έχουν εκτεθεί σε μη εξουσιοδοτημένα άτομα. Επίσης η διαθεσιμότητα αυτών των πληροφοριών μπορεί να αυξήσει και τον κίνδυνο της κλοπής ταυτότητας. Trojans, ιοί, worm s: Ένας χρήστης θα μπορούσε να μεταφορτώσει και να εγκαταστήσει μια παγιδευμένη P2P εφαρμογή που θα μπορούσε να επιβάλει σοβαρή ζημιά, να θέσει εκτός λειτουργίας έναν υπολογιστή, για να εξαλείψει ή να τροποποιήσει δεδομένα. Εάν ένας τέτοιος υπολογιστής που έχει προσβληθεί είναι μέρος του δικτύου διαχείρισης, μπορεί η δυσλειτουργία του να έχει εκτεταμένες επιπτώσεις. Ο ιός είναι μια μορφή κακόβουλου λογισμικού. Πρόκειται για ένα πρόγραμμα που αναπαράγει τον κώδικά του προσκολλώμενο σε άλλα προγράμματα, με τρόπο ώστε ο κώδικας του ιού να εκτελείται κατά την εκτέλεση προγράμματος του υπολογιστή που έχει προσβληθεί. Υπάρχουν πολλοί άλλοι τύποι κακόβουλου λογισμικού: ορισμένοι βλάπτουν μόνο τον υπολογιστή όπου έχουν αντιγραφές ενώ άλλοι μεταδίδονται σε άλλα δικτυωμένα προγράμματα. Υπάρχουν λ.χ. προγράμματα (με την ονομασία “λογικές βόμβες”) που παραμένουν αδρανή μέχρι την ενεργοποίησή τους από κάποιο γεγονός, όπως μια συγκεκριμένη ημερομηνία, π.χ. Τρίτη και 13. Άλλα προγράμματα εμφανίζονται ως καλοήθη, όταν όμως ανοίγουν εκδηλώνουν κακόβουλη επίθεση (για το λόγο αυτό αποκαλούνται “Δούρειοι Ίπποι” – Trojans).
Άλλα προγράμματα (ονομαζόμενα “σκουλήκια” – worms) δεν προσβάλλουν άλλα προγράμματα όπως ο ιός, αλλά δημιουργούν αντίγραφά τους, τα οποία με τη σειρά τους αναπαράγονται, κατακλύζοντας τελικά ολόκληρο το σύστημα. Απόφραξη εύρους ζώνης και ο διαμοιρασμός αρχείων: Οι P2P εφαρμογές όπως Kazaa,Gnutella και FreeNet επιτρέπουν σε έναν υπολογιστή να μοιράζετε αρχεία με έναν άλλο υπολογιστή που βρίσκεται κάπου αλλού στο διαδίκτυο. Ένα σοβαρό πρόβλημα που προκύπτει λόγο αυτής της λειτουργιάς τους είναι ότι οδηγούν στη βαριά κυκλοφορία, η οποία φράζει το δίκτυο. Τα πλούσια ακουστικά και τηλεοπτικά αρχεία που οι Ρ2Ρχρήστες μοιράζονται είναι πολύ μεγάλα. Με αποτέλεσμα αυτό να οδηγεί σε άσκοπη καθυστέρηση δικτύου εις βάρος άλλων εργαζόμενων-χρηστών. καθώς επίσης και για τους πελάτες ηλεκτρονικού εμπορίου. Κατασπατάληση εύρους (bandwidth). Bugs: Software bug είναι ένα λάθος, σφάλμα, αποτυχία, ή ελάττωμα σε ένα πρόγραμμα λογισμικού που το οδηγεί σε ανεπιθύμητη συμπεριφορά. Τα περισσότερα bugs προέρχονται από ανθρώπινα λάθη ή σφάλματα που γίνονται είτε στον πηγαίο κώδικα είτε στον σχεδιασμό/αρχιτεκτονική του προγράμματος, και μερικά προέρχονται από την εσφαλμένη παραγωγή κώδικα από έναν μεταγλωττιστή. Γεια να λειτουργήσει μια P2P εφαρμογή κοινής χρήσης αρχείων θα πρέπει το κατάλληλο λογισμικό να εγκατασταθεί στο σύστημα των χρηστών. Εάν αυτό το λογισμικό περιέχει ένα bug,τότε θα μπορούσε να εκθέσει το δίκτυο σε έναν αριθμό κινδύνων, με διάφορα επίπεδα δυσχέρειας προς τον χρήστη του προγράμματος. Μερικά bugs έχουν μόνο μια λεπτή επίδραση στην λειτουργικότητα του προγράμματος, και μπορούν έτσι να παραμείνουν μη ανιχνευμένα για πολύ καιρό. Μερικά άλλα όμως έχουν πιο σοβαρές επιπτώσεις όπως σύγκρουση με τις επιχειρησιακές εφαρμογές ή ακόμα και κατάρρευση του συστήματος. Πρόσβαση Backdoor: Είναι κομμάτια κώδικα που γράφονται μέσα σε εφαρμογές ή λειτουργικά συστήματα έτσι ώστε να δώσουν στους προγραμματιστές πρόσβαση σε προγράμματα χωρίς να χρειάζεται αυτοί να περάσουν από τις συνήθεις, χρονοβόρες διαδικασίες ασφάλειας της πρόσβασης. Στην ουσία είναι ‘‘τρύπες” ασφάλειας που δημιουργούνται εσκεμμένα. Τυπικά γράφονται από προγραμματιστές εφαρμογών που χρειάζονται κάποιο μέσο εξφαλμάτωσης ή ελέγχου του κώδικα που αναπτύσσουν. Αρκετά συχνά αποτελούν τροποποίηση νόμιμου λογισμικού με κακόβουλο σκοπό. Οι P2P εφαρμογές όπως KazaA, Morpheus ή Gnutella επιτρέπουν στους ανθρώπους όλου του κόσμου να μοιράζονται μεταξύ τους εφαρμογές μουσικής, βίντεο και λογισμικού. Αυτές οι εφαρμογές εκθέτουν τα στοιχεία όσον αφορά τον υπολογιστή του χρήστη σε χιλιάδες ανθρώπους στο διαδίκτυο. Αυτές οι Ρ2Ρεφαρμογές δεν σχεδιάστηκαν για τη χρήση στα εταιρικά δίκτυα και κατά συνέπεια εισάγουν σοβαρές αδυναμίες στην ασφάλεια του εταιρικού δικτύου, εάν εγκατασταθεί στα δικτυωμένα PC. Παραδείγματος χάριν εάν ένας χρήστης ξεκινήσει το Gnutella και στη συνέχεια κάνει κλικ στο εταιρικό Intranet να ελέγξει το email, ένας εισβολέας θα μπορούσε να χρησιμοποιήσει αυτό ως backdoor για να αποκτήσουν πρόσβαση στο εταιρικό δίκτυο LAN.
Μη- Κρυπτογραφημένο ΙΜ: Οι στιγμιαίες εφαρμογές μηνύματος όπως εκείνους που παρέχονται από τη AOL, τη Microsoft και το Yahoo, αποτελούν επίσης απειλή πληροφοριών για μια επιχείρηση. Πολλοί χρήστες χρησιμοποιούν αυτές τις εφαρμογές προκειμένου να επικοινωνήσουν με φίλους, να στείλουν ή να δεχθούν αρχεία, μηνύματα, καθώς αυτές οι εφαρμογές προσπαθούν να ξεγελάσουν τα προγράμματα που φιλτράρουν τις πληροφορίες που εισέρχονται και εξέρχονται από ένα δίκτυο, ώστε να περάσουν και δεδομένα που μπορεί να περιέχουν κακόβουλο λογισμικό. Ωστόσο οι χρήστες δεν συνειδητοποιούν τους κινδύνους που κρύβουν αυτές οι εφαρμογές και την πιθανή καταστροφή που μπορεί να επιφέρουν. Ποτέ δεν μπορούμε να είμαστε σίγουροι για το ποιος είναι στο άλλο άκρο της γραμμής. Μπορεί πράγματι να είναι κάποιος φίλος μας ή ένας κακόβουλος χρήστης. Οι περισσότερες από αυτές τις εφαρμογές περιέχουν τρωτά σημεία, η εκμετάλλευση των οποίων από γνώστες του είδους θα μπορούσε να δημιουργήσει σοβαρά προβλήματα. Ένα αρχείο που θα πάρουμε μπορεί να είναι μολυσμένο και να οδηγήσει με η σειρά του στη μόλυνση του συστήματος και του δικτύου γενικότερα. Λόγω της εύκολης επικοινωνίας, είναι επίσης δυνατό γιατους μη-πιστούς υπαλλήλους να συνομιλούν στους ανταγωνιστές και να αποκαλύπτουν ευαίσθητα μυστικά της επιχείρησής. Επίσης εάν αυτές οι εφαρμογές χρησιμοποιούνται για να συζητήσουν την ευαίσθητη πληροφορία, ένας επιτιθέμενος μπορεί να διαβάσει όλα τα μηνύματα που στέλνονται πέρα δώθε μέσω το δίκτυο ή το Διαδίκτυο με τη χρησιμοποίηση ενός προγράμματος διαμοιρασμού αρχείων. Εμπιστευτικότητα: To Kazaa και Gnutella δίνουν σε όλους τους πελάτες την άμεση πρόσβαση στα αρχεία που αποθηκεύονται στο σκληρό δίσκο ενός χρήστη. Κατά συνέπεια είναι δυνατό για έναν χάκερ να αποκτήσει πρόσβαση στους φακέλους και τις πληροφορίες που είναι εμπιστευτικές. Η εμπιστευτικότητα σημαίνει πρόληψη μη εξουσιοδοτημένης αποκάλυψης πληροφοριών, δηλαδή, πρόληψη από μη εξουσιοδοτημένη ανάγνωση. Επομένως, σημαίνει ότι τα δεδομένα που διακινούνται μεταξύ των υπολογιστών ενός δικτύου, αποκαλύπτονται μόνο σε εξουσιοδοτημένα άτομα. Αυτό αφορά όχι μόνο την προστασία από μη εξουσιοδοτημένη αποκάλυψη των δεδομένων αυτών καθαυτών αλλά ακόμη και από το γεγονός ότι τα δεδομένα απλώς υπάρχουν. Έτσι για παράδειγμα, το γεγονός ότι κανείς έχει φάκελο εγκληματία είναι συχνά το ίδιο σημαντικό όπως και οι λεπτομέρειες για το έγκλημα που διαπράχθηκε.
Αυθεντικότητα: Υπάρχει επίσης το ζήτημα της αυθεντικότητας. Όταν χρησιμοποιούνται τα Ρ2Ρθα πρέπει εξασφαλίζετε ότι η πρόσβαση σε πληροφορίες από ομότιμους είναι αυτοί που πραγματικά λένε ότι είναι και ότι έχουν πρόσβαση μόνο στις εξουσιοδοτημένες πληροφορίες. Αφορά στην εξασφάλιση ότι τα δεδομένα είναι απαλλαγμένα από ατέλειες και ανακρίβειες κατά τις εξουσιοδοτημένες τροποποιήσεις. Η αυθεντικότητα και η ακεραιότητα των στοιχείων μπορεί να εγγυηθεί μόνο μέσω της χρήσης των απαραίτητων διαδικασιών οι οποίες θα έχουν συμφωνηθεί ανάμεσα στους ενδιαφερομένους οργανισμούς.
6.3 Application service platform Functions map to “application” and “operation and maintenance”. 6.3.1 DApp framework DApp framework includes interfaces which support DApp development, DLT data management and DLT account management. The upper layer interface provided by the distributed ledger gives external systems efficient access to the distributed ledger data, to external applications to integrate distributed ledgers or to other distributed ledgers for mutual access, usually including RPC, API and SDK. The interface layer mainly completes data synchronization, transaction exchange, etc. The RPC interface connects peripheral components with the distributed ledger nodes over the network and to access the services provided by the distributed ledger. SDK provides a development package for other components to integrate part of the functionality of a distributed ledger. RPC and SDK should observe the following rules: Completely functional: the transactions of distributed ledger can be completed and maintained, and an intervention strategy and privilege management are operational; Portable: it can be used in a variety of applications and environment, and is not limited to one absolute software or hardware platform; Extensible and compatible: it should be as forward and backward compatible as possible, and try not to modify or minimize changes as extending functions; Easy to use: the structured design and good naming methods should be used to reduce the cost of development. Common implementation techniques include call control, serialized objects, and network components. There are various architectures which can be used, such as CORBA [b-corb], JsonRPC [b-jrpc], gRPC [b-grpc], Thrift [b-thrft], RestAPI [b-rapi], XMLRPC [b-xrpc] etc. 6.3.2 Accounting, authorization and authentication The AAA system manages the DApp users ability to access data, process data and perform data exchange based on transactions. The AAA management shall focus on three parts: Access control for DApp users to submit their transaction; Access control for nodes to access the chain network (permission control), usually being applied by private chains and consortium chain (permissioned chain); Privilege control for DApp users to operate the data and function calls via transactions. 6.3.3 Data privacy The use of cryptographic techniques to protect on-chain user data and to meet data privacy requirement for applications (result in DApps). Privacy has always been one of the obstacles to the application of distributed ledger. How to satisfy regulatory requirements and not infringe data privacy is the key to the distributed ledger industry.
Privacy protection should therefore meet the following requirements: Anonymity controls: to ensure that users can set the transaction so it is not visible to unrelated parties; High-performance: privacy-protected design must still be able to meet performance requirements; Transparent supervision: privacy protection should not evade the regulatory functions of regulatory agencies. 6.3.4 Data storage and synchronization Useful tools for end users and DApps to facilitate DApp data storage, synchronization, operation and credentials. 6.3.5 Operation and maintenance 6.3.5.1 Deployment The deployment of distributed ledger refers to the installation and use of distributed ledger services for different scenarios and users with different node permissions and service modes. According to the type, distributed ledgers are divided into public chains, consortium chains, and private chains, where their deployment methods are not the same. Permissionless DLT Permissionless DLTs generally do not make any restrictions to nodes access, and less demanding on the operating environment, the ledger nodes are relatively simple, all nodes are free to participate in consensus and read and write data. Permissioned DLT In such distributed ledgers, consensus processes can only be involved with authorized customer nodes. Authorized nodes can participate in the consensus and data read and write process according to the rules. Permissioned DLTs generally need to provide higher performance, so the operating environment requirements for consensus nodes are higher. It is recommended that such distributed ledgers use a high performance and consistent execution environment for deployment for higher performance and reliability. The deployment of permissioned DLTs can occur in the following ways: Process-based deployment – Operations staff personnel deploy nodes on the host or virtual machine to complete the configuration. This deployment is flexible. However, due to the complexity of the configuration file, the deployment is inefficient and prone to problems caused by inconsistent node environments. Container-based deployment – This involves ensuring a uniform environment within the container and encapsulating the distributed ledger in the container, then deploying the container by the operations staff. This approach is simpler to deploy than process-based deployment and more reliable. Cloud service-based deployment – Integration of distributed ledger and cloud services that facilitates rapid deployment of distributed ledger services through the cloud platform, while providing different levels of PaaS, BaaS services. 6.4 DLT applications Functions map to “application”. Multiple applications based on DLT systems, especially blockchain systems, DApps.
6.5 External services Functions map to “external interaction management” and “extensions”. The reference architecture of DLT, especially blockchain system, shall meet the requirement to balance the needs of security, decentralization, and scalability. Furthermore, decentralized systems are focusing on resolving “trust” issues in competitive business environments, therefore, not all business cases shall use decentralized systems. A hybrid system combines DLT systems with typical IT systems and can satisfy most business requirements. From a DLT perspective, external services provide solutions to cooperate with external systems. 6.5.1 Extensions Extensions include the capability to interact with non-DLT systems, 3 rd party DLT systems and/or layer 2 blockchain technology. Concerning layer 2 blockchain technology, its main purpose is to scale blockchain transaction capacity while retaining the benefits decentralization brings to a distributed protocol. Solving the scalability problem will significantly help with blockchain’s mainstream adoption. Layer 2 blockchain technology systems are those that connect to and rely on blockchain systems as a base layer of security and finality. Layer 2 solutions include plasma, state channel, sharding, raiden network, lightening network, etc. 6.5.2 External interaction/interoperation management In layer 2 solutions, the blockchain system is able to interact/interoperate with layer 2 systems. 6.5.3 External resource management To cooperate with non-DLT systems and third party DLT systems, mostly data/resource exchange transactions, resource management is required.
7 Architecture mapping of other distributed ledgers See Annex A and electronic attachments.
Annex A: Overview of architecture mapping to existing DLT platforms The applicability of the DLT reference architecture is illustrated by mapping it to 14 live DLT platforms, including some of the most popular ones. Table A.1 provides an overview of the mapping. The electronic attachment to this technical specification contains the individual platform mappings.
Κυβερνήσεις χρησιμοποιούν στοχοθετημένες διαφημίσεις στις μηχανές αναζήτησης και τα κοινωνικά μέσα ενημέρωσης, για την τροποποίηση της συμπεριφοράς.
Μια νέα μορφή «κυβερνητικής επιρροής», η οποία χρησιμοποιεί ευαίσθητα προσωπικά δεδομένα για να δημιουργήσει εκστρατείες που στοχεύουν στην αλλαγή συμπεριφοράς έχει «υπερφορτιστεί» από την άνοδο των μεγάλων εταιρειών τεχνολογίας, προειδοποίησαν ερευνητές.
Οι εθνικές και τοπικές κυβερνήσεις έχουν στραφεί σε στοχευμένες διαφημίσεις σε μηχανές αναζήτησης και πλατφόρμες μέσων κοινωνικής δικτύωσης για να «ωθήσουν» την συμπεριφορά των πολιτών, γενικότερα, διαπίστωσαν οι ακαδημαϊκοί. Η στροφή σ’ αυτό το νέο εμπορικό σήμα διακυβέρνησης προέρχεται από το πάντρεμα μεταξύ της εισαγωγής της ‘θεωρίας ώθησης’ στην χάραξη πολιτικής και μιας διαδικτυακής διαφημιστικής υποδομής που παρέχει, απρόβλεπτες ευκαιρίες, για την εκτέλεση εκστρατειών προσαρμογής συμπεριφοράς.
Μερικά από τα παραδείγματα που βρέθηκαν από το Σκωτσέζικο Κέντρο Έρευνας για το Έγκλημα και την Δικαιοσύνη (SCCJR) κυμαίνονται από ένα σχέδιο τύπου Prevent για να αποτρέψει τους νέους να γίνουν διαδικτυακοί ‘απατεώνες’ έως συμβουλές για το πώς να ανάψετε σωστά ένα κερί. Ενώ η στοχευμένη διαφήμιση είναι κοινή σε όλες τις επιχειρήσεις, ένας ερευνητής υποστηρίζει ότι η κυβέρνηση που την χρησιμοποιεί για να οδηγήσει σε αλλαγή συμπεριφοράς θα μπορούσε να δημιουργήσει έναν τέλειο βρόχο ανατροφοδότησης.
«Με την κυβέρνηση, έχετε πρόσβαση σε όλα αυτά τα δεδομένα όπου μπορείτε να δείτε σχεδόν σε πραγματικό χρόνο με ποιους πρέπει να μιλήσετε δημογραφικά, και στην συνέχεια, στην άλλη άκρη, μπορείτε να δείτε πραγματικά, «έκανε την διαφορά;», είπε ο Ben Collier, από το Πανεπιστήμιο του Εδιμβούργου. «Η κυβέρνηση που το κάνει αυτό επιβαρύνει την ικανότητά της να λειτουργεί πραγματικά».
Η αγάπη της Βρετανικής κυβέρνησης για τακτικές τροποποιήσεις συμπεριφοράς ξεκίνησε στην εποχή του David Cameron. Από την ίδρυση της ομάδας Behavioral Insight Team -ή της «μονάδας ώθησης»- στο Νο 10, οι υπουργοί έψαχναν με ανυπομονησία για τροποποιήσεις, ώστε να ελέγξουν/βοηθήσουν τους ανθρώπους να πληρώσουν φόρο αυτοκινήτου ή να ενθαρρύνουν τους ανθρώπους να αγοράσουν μόνωση σοφίτας. Τα παραδείγματα επιρροής της κυβέρνησης που αποκαλύπτονται από το SCCJR κυμαίνονται από βαθιά σοβαρά έως σχεδόν εντυπωσιακά ανόητα.
Στο ένα άκρο του φάσματος βρίσκεται το πρόγραμμα «Cyber-Prevent» της Εθνικής Υπηρεσίας Εγκλήματος, το οποίο περιλαμβάνει τον εντοπισμό των νέων που κινδυνεύουν να εμπλακούν στο έγκλημα στον κυβερνοχώρο. Ορισμένα σκέλη του προγράμματος, το οποίο βασίζεται στο σύστημα πρόληψης κατά της ριζοσπαστικοποίησης, περιλαμβάνουν παραδοσιακές επισκέψεις «knock and talk», όπου οι αξιωματικοί της NCA κάνουν μια επίσκεψη στο σπίτι για να συνεργαστούν με τους γονείς του νεαρού, ώστε να τον οδηγήσουν σε μια ‘διαφορετική’ πορεία ζωής.
Αλλά αυτό το μέρος του προγράμματος περιλαμβάνει επίσης την συλλογή σημαντικού όγκου δεδομένων από την NCA για τους νέους που επισκέπτεται, τα οποία μπορούν να χρησιμοποιηθούν για την δημιουργία προφίλ του τυπικού εφήβου «σε κίνδυνο». Αυτά τα προφίλ μπορούν στην συνέχεια να χρησιμοποιηθούν για την εκτέλεση μιας καμπάνιας «επιρροής αστυνόμευσης», χρησιμοποιώντας στοχευμένες διαφημίσεις που απευθύνονται σε εφήβους στο Ηνωμένο Βασίλειο που ενδιαφέρονται για παιχνίδια και αναζητούν συγκεκριμένες υπηρεσίες στον κυβερνοχώρο στο Google.
«Ξεκινώντας ως απλές διαφημίσεις βασισμένες σε κείμενο, η NCA τις ανέπτυξε σε μια εξάμηνη εκστρατεία σε συνεννόηση με ψυχολόγους συμπεριφοράς και χρησιμοποιώντας τα δεδομένα που συνέλεγαν από την επιχειρησιακή τους εργασία», γράφουν οι ερευνητές.
Οι διαφημίσεις συνδέονταν επίσης με μεγάλες συμβάσεις τυχερών παιχνιδιών και οι διαφημίσεις αγοράστηκαν σε ιστότοπους τυχερών παιχνιδιών.
Στο άλλο άκρο του φάσματος, μια εκστρατεία πυρασφάλειας αποφάσισε να ακολουθήσει την πιο προφανή δυνατή διαδρομή στόχευσης, είπε ο Collier:
«Το Υπουργείο Εσωτερικών καυχιόταν ουσιαστικά για την χρήση των δεδομένων αγορών των ανθρώπων μέσω κατηγοριών στόχευσης της Amazon. Βασικά τα είχαν συλλέξει έτσι ώστε αν αγοράζατε κεριά ή σπίρτα, αυτά θα χρησιμοποιηθούν για να σας στοχεύσουν με ηχητικές διαφημίσεις στο Amazon Alexa, με συμβουλές πυρασφάλειας. Έτσι, αγοράζετε τα κεριά όταν είστε έξω, επιστρέφετε σπίτι και η Amazon Alexa, αρχίζει να σας δίνει συμβουλές πυρασφάλειας».
Αν και είναι συνήθως καλό για την κυβέρνηση να επιτυγχάνει στόχους όπως η μείωση των πυρκαγιών σε σπίτια ή την πρόληψη του εγκλήματος στον κυβερνοχώρο, ο Collier και οι συνεργάτες του προειδοποιούν ότι η άνοδος της «κυβερνητικής επιρροής» θα μπορούσε να προκαλέσει βλάβη. Όχι μόνο ενθαρρύνει τμήματά της να παίζουν γρήγορα και χαλαρά με τα ευαίσθητα προσωπικά δεδομένα (χρησιμοποιώντας δεδομένα από μια προσεκτική συνέντευξη ώστε να δημιουργήσουν το προφίλ ενός τυπικού εγκληματία στον κυβερνοχώρο π.χ.) μπορεί επίσης να εστιάσει αρνητική προσοχή σε ευάλωτες και μειονεκτούσες ομάδες, με τρόπους που θα μπορούσαν να είναι καταστρεπτικές.
Ένα σύνολο διαφημίσεων κατά του ‘εγκλήματος με μαχαίρι’, για παράδειγμα, με δραπανοκατσάβιδα, στόχευε στους λάτρεις της μουσικής στο YouTube. Οι ερευνητές προειδοποιούν ότι το να ακολουθούνται σε όλο το Διαδίκτυο από αναφορές για ‘εγκλήματα με μαχαίρι’ θα μπορούσε να κάνει τους νέους πιο πιθανό να πιστεύουν ότι η μεταφορά μαχαιριού ήταν συνηθισμένη, βοηθώντας τους τελικά να πειστούν να φέρουν όπλο.
Συχνά, τέτοιες καμπάνιες ανατίθενται σε τρίτους οργανισμούς μάρκετινγκ, μια πρακτική που οι ερευνητές υποστηρίζουν ότι πρέπει να σταματήσει. «Είναι παρεμβάσεις πολιτικής πρώτης γραμμής και πρέπει να θεωρούνται ως τέτοιες, και να υπόκεινται στον ίδιο δημόσιο διάλογο, έλεγχο και λογοδοσία με άλλες τέτοιες πολιτικές», υποστηρίζουν, επειδή τελικά έχουν το «διπλό αποτέλεσμα του ανοίγματος των οικείων χώρων των πολιτών, ζουν από τον κρατικό έλεγχο από την μια πλευρά και την επέκταση των πηγών δεδομένων που χρησιμοποιεί η κυβέρνηση για να στοχεύσει την πολιτική, από την άλλη».
*** @Alex Hern τεχνολογικός συντάκτης UK /the Guardian
@Επιμέλεια/μετάφραση: OWL/terrapapers.com
Άρθρο του 2021, που τροποποιήθηκε στις 8-09-2021 για να διορθώσει το όνομα του Σκωτικού Κέντρου Έρευνας για το Έγκλημα και την Δικαιοσύνη (SCCJR).
***
ΠΟΛΛΕΣ ΑΣΚΗΣΕΙΣ -ΓΙΑ ΝΑ ΕΙΣΑΙ ΕΝΑΣ ΑΝΕΞΑΡΤΗΤΟΣ ΑΝΘΡΩΠΟΣ-
Computational power, or compute, is a core dependency in building large-scale AI.1
Amid a steadily growing push to build AI at larger and larger scale, access to compute—along with data and skilled labor—is a key component2 in building artificial intelligence systems. It is profoundly monopolized at key points in the supply chain by one or a small handful of firms.3
Industry concentration acts as a shaping force in how computational power is manufactured and accessed by tech developers. As we will show, it influences the behavior of even the biggest AI firms as they encounter the effects of compute scarcity. A recent report from Andreessen Horowitz describes compute as “a predominant factor driving the industry today,” noting that companies have spent “more than 80% of their total capital on compute resources.”4
This concentration in compute also incentivizes cloud infrastructure providers to act in ways that will protect their dominant position in the market, racing to release products before they’re ready for widespread use and behaving in ways that encourage lock-in into their cloud ecosystems.
Understanding the influence of computational infrastructure on the political economy of artificial intelligence is profoundly important: it affects who can build AI, what kind of AI gets built, and who profits along the way. It defines the contours of concentration in the tech industry, incentivizes toxic competition among AI firms5, and deeply impacts the environmental footprint of artificial intelligence6. It enables dominant firms to extract rents from consumers and small businesses dependent on their services, and creates systemic harms when systems fail or malfunction due to the creation of single points of failure. Most concerningly, it expands the economic and political power of the firms that have access to compute, cementing the control of firms that already dominate the tech industry.
Policy interventions—including industrial policy movements, export controls, and antitrust enforcement—likewise have a profound effect on who has access to compute, at what cost, and under what conditions. Thinking deliberately about policy mechanisms offers a path forward for mitigating the most harmful effects of AI. But many actors with divergent incentives are converging on compute as a leverage point for achieving their objectives: for example, cofounder of DeepMind Mustafa Suleyman recently called for sales of chips to be restricted to firms that can demonstrate compliance with safe and ethical uses of the technology,7 while others are pointing to export controls to mitigate existential risk while ignoring near-term harms.8 Any such policy interventions will require careful calibration and thought, learning from the past decade of research and evidence on the implications of artificial intelligence, as well as looking to historical case studies in which measures such as nondiscrimination policy have been utilized to target firms’ monopoly power over critical infrastructures.9
Understanding the material underpinnings of artificial intelligence is an important entry point for examining its effects on the broader public. This guide offers a primer for one key dimension: compute.
Defining “Compute”
When we use the word “compute,” we sometimes mean the number of computations needed to perform a particular task, such as training an AI model. At other times, “compute” is used to refer solely to hardware, like chips. Often, though, we use “compute” to refer to a stack that includes both hardware and software.
This stack can include:
The amount of compute used is measured in floating point operations (FLOP). In rough terms, a FLOP is a mathematical operation that enables the representation of extremely large numbers with greater precision. Compute performance is measured in floating point operations per second (FLOP/s), or how many computations a given resource can carry out in a second.
Recent progress in AI models has been made possible through deep learning, a machine learning technique that uses vast amounts of data to build layers of understanding. Deep learning has facilitated the development of models that have more generalized capabilities than we have seen before. It is enabled by the use of high-end computational resources that can perform many computations very quickly and in parallel.
Deep learning is computationally expensive by design.10 Researchers in AI have largely concluded that increasing scale is key to accuracy and performance in training deep learning models. This has driven exponentially growing demand for computing power, leading to concerns that the current pace of growth is unsustainable.11
This trend has borne out historically: before the deep learning era, the amount of compute used by AI models doubled in about 21.3 months; since deep learning as a paradigm took hold around 2010, the amount of compute used by models started doubling in only 5.7 months12. Since 2015 however, trends in compute growth have split into two: the amount of compute used in large-scale models has been doubling in roughly 9.9 months, while the amount of compute used in regular-scale models has been doubling in only about 5.7 months.13
The lack of sustainability cuts in two directions: first, there is a clear scarcity, particularly in the kinds of state-of-the-art (SOTA) chips needed for training large-scale AI models efficiently. Demand for these chips—currently Nvidia’s H100 and A100—is extremely high. Supplies are limited, leading to unconventional arrangements such as the collateralization of GPUs to raise funds,14 organizations set up to provide GPU rental services,15 and purchases of GPUs by nation-states seeking a competitive advantage.16 Demand for large amounts of compute power and the resulting scarcity are both products of public policy, and are a significant shaping force on the field’s trajectory. This puts cloud infrastructure firms like Amazon Web Services (AWS), Google Cloud, and Microsoft Azure, as well as the chip design firm Nvidia and chip fabrication firm Taiwan Semiconductor Manufacturing Company (TSMC), in a dominant position.
Large-scale compute is also environmentally unsustainable: chips are highly toxic to produce17 and require an enormous amount of energy to manufacture:18 for example, TSMC on its own accounts for 4.8 percent of Taiwan’s national energy consumption, more than the entire capital city of Taipei.19 Running data centers is likewise environmentally very costly: estimates equate every prompt run on ChatGPT to the equivalent of pouring out an entire bottle of water.20
Could future research directions lead to smaller models? To answer this question, it is helpful to look at why larger models took hold in the first place—and who benefits from perpetuating them. Sara Hooker’s concept of the hardware lottery describes the phenomenon where a research idea wins because it is the most suited to the available hardware and software. In this sense, the hardware and software determine the research direction, not the other way around.21 Deep neural networks at first represented an idea that was too ahead of its time in hardware terms, and was thus long ignored. It was only when the research on neural networks was combined with massive datasets scraped from the web, the computational resources accrued by Big Tech firms, and the incentive structures introduced by commercial surveillance that we saw the explosion of interest in building artificial intelligence systems.22 Hooker predicts that due to increasing specialization in computing, the cost of straying from the mainstream, hardware-compatible set of ideas will only increase over time.
In other words, large models today are not only compatible with the hardware available today; they also provide returns to cloud infrastructure providers that have already made massive investments in their hardware. Given the high up-front costs of obtaining GPUs and networking, as well as of building the data center infrastructures needed to run compute at scale most efficiently, the players who own this infrastructure—hyperscalers like Google Cloud, Microsoft Azure, and Amazon Web Services—have strong incentives to maximize these investments through behavior that seeks to perpetuate AI at scale, favors their ecosystem of corporate holdings, and that further locks in their dominance in cloud computing.23 Hooker sees the most promise in interventions that target the software-hardware relationship,24 while regulators around the globe are looking more deeply into concentration in the cloud ecosystem.25
Source: Jaime Sevilla et al., ‘Compute Trends Across Three Eras of Machine Learning’ (arXiv, 9 March 2022), http://arxiv.org/abs/2202.05924.
Τι είναι οι Φόρμες της Access και ποια η χρησιμότητά τους;
Οι φόρμες της Access είναι ένας όμορφος τρόπος απεικόνισης των περιεχομένων των Πινάκων (Tables) ή των Ερωτημάτων (Queries) μιας Βάσης Δεδομένων. Μια φόρμα αναφέρεται πάντα σ’ έναν πίνακα (table) ή σ’ ένα ερώτημα (query) της Access απ’ όπου και παίρνει τα δεδομένα που απεικονίζει στην οθόνη. Σ’ έναν πίνακα μπορούμε να αντιστοιχίσουμε όσες φόρμες θέλουμε, δηλ. διαφορετικούς τρόπους εμφάνισης των δεδομένων μας.
Σε μια φόρμα μπορούμε να βάλουμε δικούς μας τίτλους (επικεφαλίδες) και να τοποθετήσουμε τα πεδία σε όμορφα έγχρωμα πλαίσια, με όποιες γραμματοσειρές και σε όποιο μέγεθος γραμμάτων θέλουμε εμείς.
Μπορούμε να αλλάξουμε το χρώμα του φόντου, των γραμμάτων ή του περιθωρίου σε κάθε πλαίσιο πεδίου και να προσθέσουμε και ειδικά εφέ. Ακόμα, μπορούμε να ζωγραφίσουμε μεμονωμένα πλαίσια και ορθογώνια μέσα στη φόρμα.
Σε μια φόρμα εμφανίζεται συνήθως μία εγγραφή ανά οθόνη και με τα πλήκτρα PageUp και PageDown μπορούμε να μετακινηθούμε από εγγραφή σε εγγραφή. Κατά τα λοιπά, ισχύουν όλοι οι περιορισμοί και οι κανόνες εγκυρότητας που είχαμε θέσει όταν δημιουργήσαμε τον πίνακα στον οποίο βασίζεται η φόρμα.
Ό,τι καταχωρίσεις και διορθώσεις κάνουμε στη φόρμα, θα μπορούμε να τις δούμε και στην άποψη φύλλου δεδομένων (datasheet) του πίνακα και το αντίθετο. Απλούστατα, με τη φόρμα έχουμε έναν ωραίο τρόπο εμφάνισης των περιεχομένων ενός πίνακα, αλλά και άλλα πολλά πλεονεκτήματα.
Ποια είναι τα πλεονεκτήματα που έχει η χρήση των φορμών;
Σε μια φόρμα μπορούμε να εμφανίσουμε τιμές που προκύπτουν από υπολογισμούς των τιμών κάποιων πεδίων του πίνακα στον οποίο αναφέρεται η φόρμα. Για παράδειγμα, μπορεί να θέλουμε να βλέπουμε τον μέσο όρο των βαθμών ενός μαθητή σε μια φόρμα που αναφέρεται σε μαθητές. Δεν θα ήταν, βέβαια, σωστό να δημιουργήσουμε ένα πεδίο, όπου θα υπολογίζαμε και θα καταχωρούσαμε εμείς τον μέσο όρο, αφού ο μέσος όρος προκύπτει από υπολογισμό πάνω στις τιμές κάποιων πεδίων του πίνακα.
Για να το κάνουμε αυτό, θα πρέπει να δημιουργήσουμε ένα ειδικό χειριστήριο (control box) με το εργαλείο πλαισίου κειμένου (ab½ ), όπου θα γράψουμε τον τύπο : ([βαθμός-1]+[βαθμός-2]+…)/10, αν ο μαθητής έχει βαθμούς σε δέκα μαθήματα. Ο μέσος όρος θα υπολογίζεται τότε και θα εμφανίζεται σε κάθε εγγραφή μαθητή, χωρίς να αποτελεί ξέχωρο πεδίο.
Σε μια φόρμα μπορούμε να εμφανίσουμε και άλλη μια ή περισσότερες υποφόρμες, δηλ. φόρμες μέσα σε φόρμα, που είναι πάρα πολύ χρήσιμες για να υπάρχει άμεση ενημέρωση όταν έχουμε συσχετισμένους πίνακες “ένα προς πολλά”. Περισσότερα για τις υποφόρμες σε παρακάτω ερώτηση.
Μπορούμε, ακόμα, να εμφανίσουμε και εικόνες, ζωγραφιές, φωτογραφίες, ήχους ή και κινούμενες εικόνες (video) από άλλα προγράμματα των Windows μέσα σε ειδικά πλαίσια της φόρμας. Όλα αυτά λέγονται Αντικείμενα ΣΕΑ και περισσότερα γι’ αυτά παρακάτω.
Οι φόρμες είναι πολύ χρήσιμες όταν κάποια πεδία παίρνουν τιμές από μια συγκεκριμένη περιοχή τιμών. Για παράδειγμα, αν οι πελάτες μιας εταιρείας προέρχονται κατά το μεγαλύτερο μέρος τους από τις πόλεις Θεσ/νίκη, Κατερίνη και Λάρισα, τότε, μπορούμε σε μια φόρμα να εμφανίσουμε ένα πλαίσιο στο πεδίο πόλη, όπου θα υπάρχουν οι τρεις αυτές τιμές και θα μπορούμε να επιλέγουμε όποια τιμή θέλουμε, κάνοντας απλά κλικ πάνω της με το ποντίκι.
Αν, βέβαια, ο πελάτης είναι από μια πόλη που δεν ανήκει στη λίστα αυτή, τότε η Access μάς δίνει τη δυνατότητα να καταχωρίσουμε και τιμές εκτός λίστας. Με τον τρόπο αυτό, όμως, γλυτώνουμε από πληκτρολόγηση και αποφεύγουμε και τα λάθη. Περισσότερα, παρακάτω, στην παράγραφο Κατάλογοι και Σύνθετα Πλαίσια.
Το μόνο μειονέκτημα που έχουν οι φόρμες, είναι ότι δεν μπορούμε να δούμε ταυτόχρονα στην οθόνη πολλές εγγραφές μαζί, κάτι που μπορεί να γίνει με την προβολή φύλλου δεδομένων (datasheet).
Τι είναι η Εργαλειοθήκη και τι το Φύλλο Ιδιοτήτων;
Η εργαλειοθήκη(toolbox) είναι μια συλλογή εργαλείων με τα οποία μπορούμε να δημιουργήσουμε δεσμευμένα ή αδέσμευτα πλαίσια κειμένου, ομάδες επιλογών, κουμπιά εντολών, πλαίσια καταλόγου, σύνθετα πλαίσια, εικόνες, υποφόρμες, γραμμές και ορθογώνια.
Oi φύλλο ιδιοτήτων(properties) περιέχει όλες τις ιδιότητες ενός αντικειμένου και μπορεί να αναφέρεται σ’ ολόκληρη τη φόρμα, στο τμήμα λεπτομερειών της (details), σ’ ένα χειριστήριο, σ’ ένα πλαίσιο, σ’ ένα κουμπί εντολής και γενικά σε οποιοδήποτε αντικείμενο. Οι ιδιότητες που εμφανίζονται στο φύλλο ιδιοτήτων, χωρίζονται σε τέσσερις κατηγορίες : Format (Εμφάνιση), Data (Δεδομένα), Event (Συμβάντα), Other (Διάφορα Άλλα) και η επιλογή All (Όλα) έχει όλες τις ιδιότητες συγκεντρωμένες.
Τι είναι οι Ετικέτες και τι τα Πλαίσια Κειμένου;
Σε μια φόρμα, τα κείμενα και οι τιμές των πεδίων εμφανίζονται μέσα σε πλαίσια. Υπάρχουν, όμως, δύο είδη πλαισίων : οι ετικέτες (labels) και τα πλαίσια κειμένου (text boxes).
Οι ετικέτες είναι μηνύματα (τίτλοι, επικεφαλίδες, οδηγίες, πληροφορίες), όπου μπορούμε να γράψουμε ό,τι θέλουμε και λέγονται αδέσμευτα, γιατί απλούστατα περιέχουν σταθερό κείμενο και δεν συνδέονται με κάποιο πεδίο του πίνακα, έτσι ώστε να αλλάζουν όταν μετακινούμαστε από εγγραφή σε εγγραφή. Το πλήκτρο (εργαλείο) της εργαλειοθήκης με το οποίο δημιουργούμε ετικέτες είναι αυτό που έχει το γράμμα Α.
Τα πλαίσια κειμένου συνδέονται με κάποιο πεδίο ή πεδία του πίνακα στο οποίο βασίζεται η φόρμα. Έτσι, αν αλλάξουμε το περιεχόμενο ενός πλαισίου κειμένου, τότε αλλάζει και η τιμή του πεδίου με το οποίο είναι συνδεδεμένο. Μπορούμε, ακόμη, να χρησιμοποιήσουμε ένα πλαίσιο κειμένου για να υπολογίζουμε τιμές χρησιμοποιώντας αριθμητικές παραστάσεις. Σ’ αυτή την περίπτωση, όμως, δεν μπορούμε να αλλάξουμε τιμές, αλλά απλά κάνουμε υπολογισμούς τιμών από τις τιμές άλλων πεδίων. Το πλήκτρο (εργαλείο) της εργαλειοθήκης με το οποίο δημιουργούμε πλαίσια κειμένου είναι αυτό που έχει τα γράμματα ab½ .
Οι ετικέτες και τα πλαίσια κειμένου αποκαλούνται και χειριστήρια(control boxes) και μπορούμε να αλλάξουμε το μέγεθός τους και να τα μετακινήσουμε μαζί ή και ξέχωρα.
Τι είναι το Εργαλείο Ομάδας Επιλογών (Option Group);
Είναι ένα χρήσιμο εργαλείο με το οποίο δημιουργούμε ένα πλαίσιο όπου μπορούμε να τοποθετήσουμε μέσα ένα ή περισσότερα κουμπιά επιλογών (option buttons), πλαίσια ελέγχου (check boxes) ή κουμπιά διακόπτη (toggle buttons). Σε κάθε κουμπί μπορούμε να αντιστοιχίσουμε μια ξεχωριστή αριθμητική τιμή. Τα κουμπιά επιλογών έχουν ένα μαύρο σημάδι σ’ έναν κύκλο όταν είναι επιλεγμένα, τα πλαίσια ελέγχου έχουν ένα σημάδι O μέσα σ’ ένα τετράγωνο πλαίσιο και τα κουμπιά διακόπτη μοιάζουν με ηλεκτρικό διακόπτη.
Όταν κάνουμε κλικ με το ποντίκι σ’ ένα από τα κουμπιά επιλογών, τότε όλη η ομάδα επιλογών παίρνει αυτή την τιμή και ακυρώνονται όλες οι άλλες επιλογές. Την ομάδα αυτή επιλογών την συνδέουμε μ’ ένα πεδίο του πίνακα στο οποίο βασίζεται η φόρμα και έτσι το πεδίο αυτό ενημερώνεται με την τιμή που έχουμε επιλέξει από το αντίστοιχο κουμπί επιλογής.
Για παράδειγμα, η εταιρεία κινητής τηλεφωνίας Telestet έχει κατατάξει τους πελάτες της σε τέσσερις κατηγορίες, ανάλογα με το οικονομικό πακέτο που έχουν επιλέξει : economy, business, city και business plus. Ένας πελάτης της Telestet θα ανήκει υποχρεωτικά σε μία από τις τέσσερις παραπάνω κατηγορίες.
Για να διευκολύνουμε, λοιπόν, την καταχώριση των στοιχείων των πελατών και για να μην κάνουμε λάθη κατά την πληκτρολόγηση, μπορούμε να δημιουργήσουμε μια ομάδα επιλογών, όπου θα τοποθετήσουμε τέσσερα κουμπιά επιλογών, που το καθένα θα αντιστοιχεί σε μια από τις κατηγορίες πελατών της Telestet. Έτσι, πατώντας με το ποντίκι στην κατηγορία που θέλουμε, το αντίστοιχο πεδίο παίρνει αυτόματα την τιμή, χωρίς να χρειαστεί να την πληκτρολογήσουμε. Θα πρέπει να τοποθετήσουμε και τις αντίστοιχες ετικέτες (labels) δίπλα στην κάθε επιλογή.
Τι είναι οι Κατάλογοι και τι τα Σύνθετα Πλαίσια (List Box – Combo Box);
Είναι μια διευκόλυνση που μας παρέχει η Access και που μοιάζει με το εργαλείο ομάδας επιλογών που είδαμε στην προηγούμενη παράγραφο. Και εδώ έχουμε να κάνουμε με επιλογές από μια συγκεκριμένη περιοχή τιμών.
Είδαμε σε μια προηγούμενη παράγραφο ένα παράδειγμα με τις τρεις πόλεις (Θεσ/νίκη – Κατερίνη – Λάρισα), απ’ όπου επιλέγουμε αυτήν που θέλουμε. Αν, όμως, κάποιος πελάτης δεν μένει σε μια από τις τρεις αυτές πόλεις, τότε μπορούμε να παρακάμψουμε τις τρεις αυτές επιλογές και να δώσουμε μια καινούργια επιλογή, χωρίς να υπάρχει κανένα απολύτως πρόβλημα.
Υπάρχουν δύο ειδών λίστες τιμών : οι κατάλογοι και τα σύνθετα πλαίσια. Οι διαφορές τους είναι ότι στα σύνθετα πλαίσια υπάρχει ένα πτυσσόμενο πλαίσιο όπου μπορούμε να καταχωρίσουμε και δικές μας τιμές εκτός από τις τιμές του καταλόγου, ενώ στους καταλόγους δεν υπάρχει πτυσσόμενο πλαίσιο και οι τιμές που μπορούμε να επιλέξουμε είναι καθορισμένες.
Δημιουργούμε πρώτα τον κατάλογο ή το σύνθετο πλαίσιο και μετά το συνδέουμε με το πεδίο που θέλουμε. Η λίστα των τιμών που θα ανήκει στο σύνθετο πλαίσιο, μπορεί να προέρχεται είτε από έναν άλλον πίνακα ή να είναι μια λίστα τιμών που θα τη δημιουργήσουμε εμείς. Αν θέλουμε να περιοριστούμε μόνο στις επιλογές της λίστας επιλέγουμε Limit To List – Yes, αλλιώς επιλέγουμε Limit To List – No και μπορούμε να γράψουμε και άλλες τιμές εκτός λίστας.
Παράδειγμα με δική μας λίστα τιμών είδαμε προηγουμένως. Υπάρχει, όμως, και περίπτωση να πάρουμε τιμές από έναν άλλον πίνακα; Και βέβαια. Αν καταχωρούμε τις παραγγελίες των πελατών μας, τότε πρέπει να δίνουμε σε κάθε παραγγελία και τον κωδικό ή το επώνυμο του πελάτη. Δεν μπορούμε να θυμόμαστε, βέβαια, όλους τους κωδικούς ή όλα τα επώνυμα των πελατών.
Έτσι, επιλέγουμε για λίστα τιμών τις τιμές του πίνακα πελατών και στο πλαίσιο όπου θα πρέπει να γράψουμε τον κωδικό του πελάτη μέσα στη φόρμα των παραγγελιών, επιλέγουμε τον πελάτη που θέλουμε από τη λίστα των πελατών, χωρίς να ανησυχούμε αν γράψαμε σωστά τον κωδικό του ή το επώνυμό του. Σ’ αυτή την περίπτωση, η τιμή που θα επιλέξουμε πρέπει οπωσδήποτε να είναι από τη λίστα των πελατών (Limit To List – Yes).
Τι είναι τα Αντικείμενα ΣΕΑ (OLE Objects);
Είναι ειδικά πλαίσια που μπορούμε να ορίσουμε μέσα σε μια φόρμα, όπου μπορούμε να εμφανίσουμε εικόνες, οι οποίες να είναι σταθερές, δηλ. η εικόνα να είναι η ίδια για όλες τις εγγραφές, ή για κάθε εγγραφή του πίνακα να υπάρχει μια ξεχωριστή εικόνα. Αντί για εικόνα, μπορεί να υπάρχει μια ζωγραφιά, ένα εικονίδιο ήχου ή ακόμα και μια καταχώριση video (κινούμενη εικόνα).
Τι είναι τα Κουμπιά Εντολών (Command Buttons);
Είναι ειδικά πλήκτρα στα οποία μπορούμε να αντιστοιχίσουμε μια μακροεντολή ή μια διαδικασία της γλώσσας προγραμματισμού Visual Basic for Applications (VBA) που έχει η Access. Δημιουργούμε αυτό το πλήκτρο μέσα στη φόρμα, του δίνουμε ένα χαρακτηριστικό όνομα και όταν κάνουμε κλικ πάνω του με το ποντίκι, τότε εκτελείται η αντίστοιχη μακροεντολή ή η διαδικασία. Το ποια μακροεντολή ή διαδικασία θα εκτελεστεί, το ορίζουμε στον πίνακα των ιδιοτήτων του κουμπιού εντολών.
Μια μακροεντολή ή μια διαδικασία μπορεί να ανοίγει μια φόρμα ή μια αναφορά, να κάνει μια εκτύπωση ή έναν έλεγχο εγκυρότητας δεδομένων κ.ά.
Τι είναι η Υποφόρμα (SubForm);
Η υποφόρμα είναι μια φόρμα που είναι ενσωματωμένη μέσα σε μια κύρια φόρμα. Για παράδειγμα, αν έχουμε δημιουργήσει μια φόρμα για τους πελάτες μιας εταιρείας και θέλουμε συγχρόνως να βλέπουμε στην οθόνη μας και ποιες παραγγελίες έχει κάνει ο κάθε πελάτης, τότε χρησιμοποιούμε το ειδικό εικονίδιο για τη δημιουργία υποφόρμας, επιλέγουμε τον πίνακα των παραγγελιών και έτσι βλέπουμε στην οθόνη μας για τον κάθε πελάτη και όλες τις παραγγελίες του.
Για να μπορέσουμε να δημιουργήσουμε, βέβαια, μια υποφόρμα, θα πρέπει να υπάρχει μια σχέση “ένα προς πολλά” ανάμεσα στον πίνακα της κύριας φόρμας και στον πίνακα που θα δώσει τα στοιχεία του στην υποφόρμα.
Europe: The EU AI Act’s relationship with data protection law: key takeaways
On 13 March 2024, the European Parliament plenary session formally adopted at first reading the EU AI Act. The EU AI Act is now expected to be formally adopted in a few weeks’ time. Following publication in the Official Journal of the European Union, it will enter into force 20 days later.
Artificial intelligence (“AI”) systems rely on data inputs from initial development, through the training phase, and in live use. Given the broad definition of personal data under European data protection laws, AI systems’ development and use will frequently result in the processing of personal data.
At its heart, the EU AI Act is a product safety law that provides for the safe technical development and use of AI systems. With a couple of exceptions, it does not create any rights for individuals. By contrast, the GDPR is a fundamental rights law that gives individuals a wide range of rights in relation to the processing of their data. As such, the EU AI Act and the GDPR are designed to work hand-in-glove, with the latter ‘filing the gap’ in terms of individual rights for scenarios where AI systems use data relating to living persons.
Consequently, as AI becomes a regulated technology through the EU AI Act, practitioners and organisations must understand the close relationship between the EU data protection law and the EU AI Act.
1. EU data protection law and AI systems
1.1 The GDPR and AI systems
The General Data Protection Regulation (“GDPR”) is a technology-neutral regulation. As the definition of “processing” under the GDPR is broad (and in practice includes nearly all activities conducted on personal data, including data storage), it is evident that the GDPR applies to AI systems, to the extent that personal data is present somewhere in the lifecycle of an AI system.
It is often technically very difficult to separate personal data from non-personal data, which increases the likelihood that AI systems process personal data at some point within their lifecycle.
While AI is not explicitly mentioned in the GDPR, the automated decision-making framework (article 22 GDPR) serves as a form of indirect control over the use of AI systems, on the basis that AI systems are frequently used to take automated decisions that impact individuals.
In some respects, there is tension between the GDPR and AI. AI typically entails the collection of vast amounts of data (in particular, in the training phase), while many AI systems have a broad potential range of applications (reflecting the imitation of human-like intelligence), making the clear definition of “processing purposes” difficult.
At the same time, there is a clear overlap between many of the data protection principles and the principles and requirements established by the EU AI Act for the safe development and use of AI systems. The relationship between AI and data protection is expressly recognised in the text of the EU AI Act, which states that it is without prejudice to the GDPR. In developing the EU AI Act, the European Commission relied in part on article 16 of the Treaty on the Functioning of the European Union (“TFEU”), which mandates the EU to lay down the rules relating to the protection of individuals regarding the processing of personal data.
1.2 Data protection authorities’ enforcement against AI systems
Before the EU AI Act, the EU data protection authorities (“DPA”) were among the first regulatory bodies to take enforcement action against the use of AI systems. These enforcement actions have been based on a range of concerns, in particular, lack of legal basis to process personal data or special categories of personal data, lack of transparency, automated decision-making abuses, failure to fulfil data subject rights and data accuracy issues.
Examples of DPA enforcement actions are already lengthy. The most notable ones include the Italian DPA’s temporary ban decision on OpenAI’s ChatGPT, the Italian DPA’s Deliveroo fine in relation to the company’s AI-enabled automated rating of rider performance, the French DPA’s Clearview AI fine, a facial recognition platform that scrapes billions of photographs from the internet and the Dutch DPA’s fine on the Dutch Tax and Customs Administration for various GDPR infringements in relation to an AI-based fraud notification facility application.
As the DPAs shape their enforcement policies based in part on public concerns, and as public awareness of and interest in AI continues to rise, it is likely that DPAs will continue to sharpen their focus on AI (also see section 6 for DPAs as a potential enforcer of the EU AI Act).
2. Scope and applicability of the GDPR and EU AI Act
2.1 Scope of the GDPR and the EU AI Act
The material scope of the GDPR is the processing of personal data by wholly or partly automated means, or manual processing of personal data where that data forms part of a relevant filing system (article 2 GDPR). The territorial scope of the GDPR is defined in article 3 GDPR and covers different scenarios.
Consequently, the GDPR has an extraterritorial scope, meaning that: Controllers and processors established in the EU processing in the context of that establishment must comply with the GDPR even if the processing of personal data occurs in a third country. Non-EU controllers and processors have to comply with the GDPR if they target or monitor individuals in the EU.
On the other hand, the material scope of the EU AI Act is based around its definition of an AI system. Territorially, the EU AI Act applies to providers, deployers, importers, distributors, and authorised representatives (see, section 2.2 for details).
Unlike the GDPR, the EU AI Act has a robust risk categorisation, and it brings different obligations to the different AI risk categories. Most obligations under the EU AI Act apply to high-risk AI systems only (covered in article 6 and Annex III EU AI Act). Various AI systems are also subject to specific obligations (such as general-purpose AI models) and transparency obligations (such as emotional categorisation systems).
2.2 Interplay between roles under the GDPR and the EU AI Act
As the GDPR distinguishes between controllers and processors, so the EU AI Act distinguishes between different categories of regulated operators.
The provider (the operator who develops an AI system or has an AI system developed) and the deployer (the operator under whose authority an AI system is used) are the most significant in practice.
Organisations that process personal data in the course of developing or using an AI system will need to consider the roles they play under both the GDPR and the EU AI Act. Some examples follow.
Example 1: provider (the EU AI Act) and controller (the GDPR)
Example 2: deployer (EU AI Act) and controller (the GDPR)
A company (A) that processes personal data in the context of training a new AI system will be acting as both a provider under the EU AI Act and as a controller under the GDPR. This is because the company is developing a new AI system and, as part of that development, is taking decisions about how to process personal data for the purpose of training the AI system.
A company (B) that purchases the AI system described in Example 1: provider (EU AI Act) and controller (the GDPR) from company A and uses it in a way that involves the processing of personal data (for example, as a chatbot to talk to customers, or as an automated recruitment tool) will be acting as both a deployer under the EU AI Act and as a separate controller under the GDPR for the processing of its own personal data (that is, it is not the controller for the personal data used to originally train the AI system but it is for any data it uses in conjunction with the AI).
More complex scenarios may arise when companies offer services that involve the processing of personal data and the use of an AI system to process that data. Depending on the facts, the customers of such services may qualify as controllers or processors (under the GDPR) although they would typically be deployers under the EU AI Act.
These examples raise important questions about the relationship between the nature of roles under the EU AI Act and their relationship to roles under the GDPR which are still to be resolved in practice. Companies that develop or deploy AI systems should carefully analyse their roles under the respective laws, preferably prior to the kick-off of relevant development and deployment projects.
3. Relationship between the GDPR principles and the EU AI Act
The GDPR is built around the data protection principles set out in article 5 GDPR. These principles are lawfulness, fairness, transparency, purpose limitation, data minimisation, accuracy, storage limitation, integrity and confidentiality.
On the other hand, the first intergovernmental standard on AI, the recommendation on artificial intelligence issued by the OECD (OECD Recommendation of the Council on Artificial Intelligence, “OECD AI Principles”) introduces five complementary principles for responsible stewardship of trustworthy AI that have strong links to the principles in the GDPR: Inclusive growth, sustainability and well-being, human centred-values, fairness, transparency, explainability, robustness, security, safety and accountability.
The EU AI Act also refers to general principles applicable to all AI systems, as well as specific obligations that require the principles to be put in place in certain methods. The EU AI Act principles are set out in recital 27 and are influenced by the OECD AI Principles and the seven ethical principles for AI developed by the independent High-Level Expert Group on AI (HLEG). Although recitals do not have the same legally binding status as the operative provisions which follow hem and cannot overrule an operative provision, they can help with interpretation and to determine meaning.
Recital 27 EU AI Act refers to the following principles: Human agency and oversight, technical robustness and safety, privacy and data governance, transparency, diversity, non-discrimination, fairness, social and environmental wellbeing. Some of these principles already materialise through specific EU AI Act obligations: Article 10 EU AI Act prescribes data governance practices for high-risk AI systems, article 13 EU AI Act deals with transparency, articles 14 and 26 EU AI Act introduce human oversight and monitoring requirements, article 27 EU AI Act introduces the obligation to conduct fundamental rights impact assessments for some high-risk AI systems.
Understanding the synergies and differences between the GDPR principles and the EU AI Act principles will allow organisations to leverage their existing knowledge of GDPR and their existing GDPR compliance programmes. This is therefore a crucial step to lower compliance costs. The full practice note includes comprehensive tables that compare the practicalities in this regard.
4. Human oversight under the EU AI Act and automated decision-making under the GDPR
Under article 22 GDPR, data subjects have the right not to be subject to solely automated decisions involving the processing of personal data that result in legal or similarly significant effects. Where such decisions are taken, they must be based on one of the grounds set out in article 22(2) GDPR.
Like the GDPR, the EU AI Act is also concerned with ensuring that fundamental rights and freedoms are protected by allowing for appropriate human supervision and intervention (the so called “human-in-the-loop” effect).
Article 14 EU AI Act requires high-risk AI system to be designed and developed in such a way (including with appropriate human-machine interface tools) that they can be effectively overseen by natural persons during the period in which the AI system is in use. In other words, providers must take a “human-oversight-by-design” approach to developing AI systems.
According to article 26.1 EU AI Act, the deployer of an AI system must take appropriate technical and organisational measures to ensure its use of an AI system is in accordance with the instructions of use accompanying the system, including with respect to human oversight.
The level of human oversight and intervention exercised by a user of an AI system may be determinative in bringing the system in or out of scope of the automated decision-making framework under the GDPR. In other words, a meaningful intervention by a human being at a key stage of the AI system’s decision-making process may be sufficient to ensure that the decision is no longer wholly automated for the purposes of article 22 GDPR. Perhaps more likely, AI systems will be used to make wholly automated decisions, but effective human oversight will operate as a safeguard to ensure that the automated decision-making process is fair and that an individual’s rights, including their data protection rights, are upheld.
5. Conformity assessments and fundamental rights impact assessments under the EU AI Act and the DPIAs under the GDPR
Under the EU AI Act, the conformity assessment is designed to ensure accountability by the provider with each of the EU AI Act’s requirements for the safe development of a high-risk AI system (as set out in Title III, Chapter 2 EU AI Act). Conformity assessments are not risk assessments but rather demonstrative tools that show compliance with the EU AI Act’s requirements.
The DPIA, on the other hand, is a mandatory step required under the GDPR for high-risk personal data processing activities.
Consequently, there are significant differences in terms of both purpose and form between a conformity assessment and a DPIA. However, in the context of high-risk AI systems, the provider of such systems may also need to conduct a DPIA relation to the use of personal data in the development and training of the system. In such case, the technical documentation that are drafted for conformity assessments may help establishing the factual context of a DPIA. Similarly, the technical information may be helpful to a deployer of the AI system that is required to conduct a DPIA in relation to its use of the system.
The requirement under the EU AI Act to conduct a fundamental rights impact assessment (“FRIA”) is similar, conceptually, to a DPIA. As with a DPIA, the purpose of a FRIA is to identify and mitigate risks to the fundamental rights of natural persons, in this case arising from the deployment of an AI system. For more details regarding the FRIA, seeFundamental Rights Impact Assessments under the EU AI Act: Who, what and how?.
Practically speaking, organisations generally already have governance mechanisms in place to bring legal, IT and business professionals together for impact assessments such as the DPIA. When it comes to a FRIA, such mechanisms can be leveraged. As with a DPIA, the first step is likely to consist of a pre-FRIA screening to identify the use of an in-scope high-risk AI system (recognising that, as a good practice step, organisations may choose to conduct FRIAs for a wider range of AI systems than is strictly required by the EU AI Act).
6. National competent authorities under EU AI Act and DPAs
Under the EU AI Act, each member state is required to designate one or more national competent authorities to supervise the application and implementation of the EU AI Act, as well as to carry out market surveillance activities.
The national competent authorities will be supported by the European Artificial Intelligence Board and the European AI Office. The most notable duty of the European AI Office is to enforce and supervise the new rules for general purpose AI models.
The appointment of the DPAs as enforcers of the EU AI Act will solidify the close relationship between the EU GDPR and the EU AI Act.
2.3.3 Electron and Bremsstrahlung Dose Analysis In contrast to protons, the relatively small mass of electrons causes them to be deflected easily by collisions with atomic electrons and nuclei. This in turn causes them to produce bremsstrahlung (or X-rays), which is much more penetrating than the electrons. Also, the use of electron range-energy relationships (refs. 52 and 78) and the straightahead approximation to determine electron dose are consequently not as valid as for protons because of large variations of individual electron transmission about the average transmission (i.e., straggling). Although crude estimates of electron transport and dose can be made on the basis of the practical or effective range (ref. 49), these estimates are generally too high. The error ranges from negligible for zero shielding to an order of magnitude or more as shielding thickness increases (ref. 54). Several electron Monte Carlo analytical schemes have been developed that are capable of performing accurate and detailed electron-transport analysis in one dimension (e.g., refs. 66, 79, 80, and 81) and in two or three dimensions (ref. 81). The use of these programs for practical shield design is time consuming; therefore, Monte Carlo calculations have been performed to generate parametric, one-dimensional, electron transmission data (ref. 82) for application to the point-kernel analysis of three-dimensional systems. Application of the point-kernel method to electrons is exactly analogous to that discussed for protons. A summary of experimental data on electron transmission is given in reference 83; comparisons with theory are given in refs. 79 and 83. Because trapped electrons are stopped by relatively thin shielding [the practical range is approximately 4 g/cm2 per MeV (1.603 x J) of energy] , the bremsstrahlung dose is often dominant over the electron dose because of the greater penetrability of bremsstrahlung. Thus, in some cases it is an important radiation protection consideration. A comprehensive review of bremsstrahlung interaction is given in reference 84; recent detailed experimental data on bremsstrahlung production are presented in references 83, 85, and 86; comparisons with theory are given in references 79, 83, and 86. The theory of electron bremsstrahlung production and its transport through matter is sufficiently accurate for the design of space radiation protection. As in electron transport, parametric Monte Carlo analyses of bremsstrahlung transport (ref. 87) are useful for generating dose-attenuation kernels for application to the design of radiation protection. Monte Carlo codes for performing detailed analysis of bremsstrahlung production and transport are described in references 80 (one-dimensional analysis) and 8 1 (one-, two-, or three-dimensional analysis). As in the case of protons, there are design-oriented computer programs for economically performing electron and bremsstrahlung dose analysis (e.g., refs. 54, 65, and 66) in one-dimensional laminated shields. These programs are suitable for parametric studies and can be used with complex-geometry computer programs (e.g., refs. 65, 69, and 70) to analyze three-dimensional configurations. Analysis of electron and bremsstrahlung dose using these programs is sufficiently accurate for most design situations. The greatest uncertainty is in the use of one-dimensional electron transmission data to calculate electron dose in geometrically complex systems. Uncertainty in the results of dose analysis generally increases as the geometrical complexity of the system increases. The uncertainty is usually greater for electron dose than for bremsstrahlung dose. For analyses based on the point-kernel method, electron dose may be in error by a factor of 2 or more (ref. 88); results of explicit Monte Carlo analyses provide the greatest achievable accuracy. References 72, 73, and 89 summarize the technology for the analysis of electron and bremsstrahlung radiation protection; reference 89 presents an overall summary. Reference 90 presents a comparison of the results of the analyses obtained with several electron transport codes.
2.4 Shielding Design The foregoing discussion has covered the state of the art for determining the radiation dose when a completely specified set of conditions is given. For the more general objective of shield design, two approaches are available. The first and more common approach is the iterative analysis of progressively improved designs; the second involves direct numerical optimization.
The first approach can be tedious, but it is applicable in principle to any level of system complexity and dose-analysis sophistication. The second approach is generally limited to the poin t-kernel method utilized by complex-geometry programs because it is impractical to use more exact methods in an automated or semiautomated optimization procedure. The second approach of direct numerical optimization is particularly appropriate for geometrically complex systems with many parameters and multiple nonlinear constraints. Although computer programs of various degrees of sophistication have been developed for handling such problems, few have been published in the open literature. This approach is particularly appropriate for proton and alpha shielding because the point-kernel method is rather accurate for protons and alphas, even for highly heterogeneous systems. A program using the second approach is described in reference 9 1. It handles multiple time-dependent space- and onboard-radiation sources, generalized quadric geometry, multiple potential shield regions (including split shields that can be located on the walls of the crew compartment, on the walls of a biowell, and on mobile astronauts), and multiple dose constraints (based on multiple body-organ dose criteria and the specified time-weighted positions of occupants of the crew compartment). The inherent shielding worth of the unshielded vehicle is accounted for, and, for a minimum mass system, all shield dimensions are determined by automatic iteration. The limitations of this program are the same as those of the state of the art of complex-geometry dose analysis. Unclassified examples of radiation analysis and shield design for complex systems are given in references 91 and 92.
2.5 Testing Existing particle-accelerator and radioisotope facilities do not have the capability of simulating the space radiation environment in terms of energy spectrum or capability of accommodating sizable exposure areas. Consequently, the state of the art for testing space radiation protection is severely limited. Several experimental approaches have been considered, but no generally acceptable criteria for applying them to the testing of specific system designs have been defined. The approaches considered are as follows:
0 Measurement of radiation transport through representative space-vehicle structures or components 0 Measurement of the mass distribution of the space vehicle
0 Unmanned experiments launched into space to establish experimentally the separate and combined uncertainties caused by the radiation environment and theoretical methods of dose prediction
Instrumented flight tests of a space vehicle to eliminate the combined uncertainties associated with the trapped radiation environment, mass distribution, and theoretical methods of dose prediction. Except for the last approach, these do not represent system testing in the usual sense, but are attempts to reduce experimentally the uncertainty involved in the radiation protection design process. An excellent summary of the status of the last two approaches is given in reference 4.
2.5.1 Measurement of Radiation Transmission Although measurements have been made for individual components and for instrumented research probes, few have been made in direct support of a space-vehicle project. Some measurements of this kind were made early in the Apollo program.
2.5.2 Measurement of Mass Distribution Measurements of the mass distribution have been made for the Apollo command module. Measurements have also been made for Gemini, but not as part of the normal development test program. In all cases, a gamma-probe device was used (ref. 93). Comparisons of the difference between calculated doses based on the estimated mass distribution and calculated doses based on the measured mass distribution indicated that the results based on the estimated mass distribution were high by a factor of 2.7 to 3.5 for Gemini, and by a factor of 1.5 to 1.7 for the Apollo command module (ref. 94). The range in the factors is caused by the several different proton environment models that were analyzed to assess the influence of energy spectra on the comparisons.
2.5.3 Unmanned Experiments Unmanned experiments have been conducted as research projects (refs. 75, 95, and 96). The mass distributions of the systems were accurately known. Comparisons between theoretical predictions and measurements showed that the only serious discrepancy was caused by insufficient knowledge of the space-radiation environment. For example, reference 94 indicates that for thin shielding (less than 1 g/cm2), the electron and proton environments described in references 23 and 26 resulted in calculated doses that in most cases disagreed with measured values by approximately +40 percent. For greater shielding thicknesses (3 to 4 g/cm2), the calculated proton dose was low by a factor that varied from approximately 2 to 10, depending upon the magnitude of the apparent error in the model environment energy spectra.
2 5.4 Instrumented Flight Tests Space vehicle flight tests have been made which included onboard radiation detectors. Comprehensive radiation protection analyses based on inflight data have, for Project Mercury and the Gemini program, been made only for data gathered during manned operational missions (e.g., refs. 97,98, and 99). However, for the Apollo program, the unmanned flight tests of Apollos 4 and 6 were instrumented and the measurements analyzed. A review of inflight dosimetry is given in reference 4.
CRITERIA The space vehicle shall be designed to withstand the space radiation environment expected during the mission, without unduly endangering mission success or exceeding acceptable risk to astronauts. Sufficient space radiation protection shall be provided so that the specified allowable radiation dose and/or dose-rate criteria are not exceeded. 3.1 Space Radiation Environment The space radiation encountered during the mission shall be determined on the basis of the mission profile (including date) and available descriptions of the space radiation environment. Radiation sources to be accounted for are solar cosmic rays, trapped radiation, and galactic cosmic rays. The uncertainties in significant parameters (e.g., flux intensity, energy spectrum, and temporal variations) characterizing each radiation source shall be accounted for. 3.2 Allowable Radiation Doses Allowable radiation doses shall be established for all radiation-sensitive materials and components included in the space vehicle. The allowable doses shall not exceed amounts that would result in excessive radiation damage to the materials or components, taking the radiation source type and energy spectrum into consideration. Allowable space radiation doses shall reflect the presence of onboard radiation sources. The allowable doses shall be expressed in terms of explicitly defined units. Both dose rate and mission-integrated dose shall be considered.
3.3 Dose Analysis Analysis of the doses and dose rates for each potentially critical component or system shall, when practical, account for the following factors, as applicable: Spectral, temporal, and directional characteristics of each primary and secondary radiation involved Spatial distribution and composition of the space-vehicle mass and its contents, including occupants Time-dependence of significant masses and their locations (e.g., occupants, propellant, stores, equipment, and jettisonable structure) Appropriate relationships which express allowable doses in terms of radiation fluences Finite extent of surfaces or volumes of potentially critical components and systems Estimates of the uncertainties in calculated critical doses and dose rates. 3.4 Shielding Design Shielding shall be provided if the inherent protection afforded by the space vehicle is ‘ not sufficient to prevent the allowable radiation doses and dose rates from being exceeded for the duration of the mission. If radiation shielding is required, it shall be designed to ensure environmental compatibility and structural adequacy under all conditions of combined radiation, thermal, and mechanical environments. 3.5 Testing When analytical results are based on data that have not been demonstrated to be adequate, the data shall be confirmed or modified by tests that simulate the flight conditions as closely as possible.
(TO BE CONTINUED)
SOURCE NATIONAL AERONAUTICS AND SPACE ADMINISTRATION 1970
Νομίζεις πως η μέρα έχει 24 ώρες; Είναι επιστημονικά αποδεδειγμένο ΛΑΘΟΣ.
«Δεν υπάρχει ο χρόνος που ρέει προς μια κατεύθυνση και κυριολεκτικά χρόνος σε συμπαντική κλίμακα ΔΕΝ υφίσταται» Richard Feynman.
«Να είναι οι μέρες σου γρήγορες σαν αστραπή και να ζεις μέσα σε μια στιγμή χιλιάδες χρόνια». Κρισναμούρτι.
Στον νέο κόσμο (με αυτόν τον Ηλιο στον ουρανό του) ο άνθρωπος είναι αιχμάλωτος, κυριολεκτικά φυλακισμένος του Χρόνου, είναι αιχμάλωτος σε έναν αριθμητικό υπολογισμό ωρών, λεπτών, ετών. Ο χρόνος ποτέ δεν φτάνει και αν κάποια στιγμή έχει λίγο παραπάνω ή δεν ξέρει τι να τον κάνει ή τον σπαταλάει σε ανοησίες! Τα ποιοτικά χαρακτηριστικά του δεν υπάρχουν και ούτε που ξέρει ο άνθρωπος αν υπάρχει αυτό που δεν έχει. Πάντα έτσι ήταν στο γραμμικό κόσμο του ασήμαντου κι ενεργοβόρου εγώ και του νου, ο άνθρωπος κι όλα τα όντα που συνυπάρχουν μαζί του, οργανικά και ανόργανα, είναι κάτω από την κηδεμονία, την εξουσία και τα καπρίτσια του χρόνου.
Κακώς λένε ότι το αντίθετο της Ζωής είναι ο Θάνατος, δεν είναι, ο Χρόνος είναι.
Υπάρχει ο χρόνος;
Όπως τον αντιλαμβανόμαστε και όπως μας χρησιμοποιεί του στυλ “Θέλω να κάνω αυτό ή το άλλο αλλά δεν έχω χρόνο” ή “Δεν προλαβαίνω τρέχω όλη την ώρα” ή “καλή νέα χρονιά” κι άλλα τέτοια όμορφα κι ανόητα λόγια και σκέψεις σου δίνουν την εντύπωση ότι ο χρόνος υπάρχει. Αλλά η σύγχρονη επιστήμη και σχεδόν η Κβαντική θεωρία αλλά πιο ολοκληρωμένα η θεωρία του Χάους και των Fractal λένε ότι ο χρόνος όπως τον μετράς καθημερινά, είτε τον κυνηγάς είτε σε κυνηγάει, Δεν υπάρχει. Τουλάχιστον όχι, με την έννοια που σε έχουν μάθει να του δίνεις.
Σε κάποιες Πνευματικές κοινωνίες ο χρόνος είναι Ενέργεια του Σύμπαντος. Ένα ποτάμι που πρέπει να διαβούμε πλέοντας, ενώ στις σκληρές μεταβιομηχανικές κοινωνίες ο χρόνος είναι απρόσωπος, εξωτερικός, ξέχωρος από την πνευματικότητα. Όσο υπάρχει η ξεπερασμένη πλέον αντίληψη ότι ο Χρόνος είναι μια ευθεία γραμμή που ξεκινάει από κάπου στο άγνωστο και καταλήγει κάπου αλλού στο μακρινό μέλλον, τόσο θα είναι δύσκολο να ερμηνεύσεις, αλλά και να αξιοποιήσεις τις Πνευματικές κι Ενεργειακές διαστάσεις του.
Η Θεωρία του Χάους αλλά και η Κβαντική θεωρία αντικαθιστούν την γραμμή (γραμμικός χρόνος) με μια ατέλειωτη πολύπλοκη σχηματική παράσταση Fractal διάστασης. Σε κάθε κλίμακα μεγέθυνσης το Fractal αποκαλύπτει καινούργια σχήματα και νέους ατελείωτους δαιδάλους.
Ποιό απλά, κάθε τι που φαίνεται με την πρώτη ματιά γραμμικό δηλ. μια ευθεία μπορεί, αν μελετηθεί σε βάθος να εμφανίζει στροφές, καμπύλες, αραβουργήματα σε Fractal ατελείωτες λεπτομέρειες. Άλλωστε η θεωρία του Χάους δηλώνει ξεκάθαρα πως τίποτε δεν υπάρχει ευθεία στην φύση. Δεν υπάρχουν ευθείες γραμμές. Άρα ο χρόνος πως μπορεί να είναι γραμμικός; Πως μπορεί κάτι τόσο Πνευματικό όπως ο ΧωροΧρόνος να είναι μια ευθεία γραμμή όταν τίποτε δεν είναι γραμμικό;
Υπάρχουν δισεκατομμύρια δισεκατομμυρίων σύμπαντα που σε κάποια από αυτά ο χρόνος όπως τον ξέρεις εδώ σε αυτό το Σύμπαν, όπως τον μετράς με το ακριβό σου ρολόι, πολύ απλά δεν υπάρχει. Τώρα πως εσύ καταφέρνεις να μην έχεις κάτι που δεν υπάρχει; Αυτή είναι μια καλή ερώτηση … κι αν κάνεις καλές ερωτήσεις θα έχεις και καλές απαντήσεις.
Ο χρόνος όχι μόνο δεν υπάρχει “πάντα” αλλά δεν υπάρχει και “παντού”
Η Κβαντική και η θεωρία της Σχετικότητας, δεν θεωρούν τον χρόνο ως απόλυτο. “Υπάρχει όμως πάντα” λέει. Αλλά η Κβαντική δίνει και μια άλλη διάσταση στο θέμα “Χρόνος” Χρησιμοποιώντας τον ισομορφισμό του Sidis, μπορούμε να ισχυριστούμε ότι όντως ο χρόνος υπάρχει πάντα. Το πρώτο πρόβλημα που προκύπτει είναι, αν υπάρχει ο χρόνος παντού και όχι πάντα, εφόσον υπάρχουν και άλλες διαστάσεις στο χωροχρόνο, διότι η λέξη “πάντα” είναι αποκλειστικά χρονική.
Υπάρχει, λοιπόν, ένας χώρος όπου δεν υπάρχει ο χρόνος; Αν και είναι φαινομενικά παράδοξο, η ίδια η κβαντική θεωρία μας επιτρέπει να απαντήσουμε θετικά. Για να γίνει αυτό πρέπει και αρκεί να εισαγάγουμε το διάστημα του Planck. Στην ουσία, υπάρχει ένα όριο που δεν μπορούμε να ξεπεράσουμε μέσα στο διακριτό χωροχρόνο. Συνεπώς, όχι μόνο ο χρόνος δεν είναι απόλυτος, μα επιπλέον δεν αποτελεί αναγκαστικά ένα συνεχές στοιχείο.
Υπάρχει μόνο και μόνο για σένα, εκεί που μπορείς να του δώσεις ένα νόημα. Όμως αυτό το νόημα δεν είναι αντικειμενικό και γι’ αυτόν το λόγο υπάρχει αυτή η απορία. Αν όμως αποδεχτούμε ότι υπάρχει Κβάντωση της Ενέργειας και του Χώρου, είναι φυσιολογικό να γενικεύσουμε αυτή την έννοια και στο Χρόνο εφόσον ο ΧώροΧρόνος αποτελεί μια ενιαία οντότητα.
Αυτές οι μη συνεχόμενες υπάρξεις του χώρου προσφέρουν δυνατότητες ερμηνείας του διαστήματος του χρόνου με τις μικροτοπικές αλλαγές φάσης. Ο χρόνος με αυτόν τον τρόπο έχει μια γεωμετρία που δεν είναι πια γραμμική ή μονοδιάστατη τυπλογικά κι αυτή η γεωμετρία μπορεί να είναι και μορφοκλασματική εφόσον η θεωρία των Fractal μπορεί να κωδικοποιήσει τον Χώρο Με άλλα λόγια, ο χρόνος παρουσιάζεται ως μια πολυπλοκότερη έννοια που εμπεριέχει μη κλασικά στοιχεία.
Κατά τον Heidegger, ο χρόνος δεν είναι ένα πράγμα υπάρχον, αλλά μια εκτύλιξις η οποία γίνεται εις την ενότητα των κινήσεών της. Η κριτική της εννοίας του χρόνου είναι ανάλογος προς την του χώρου. Ο απόλυτος χρόνος, ανεξάρτητος μεταβλητών, είναι φανταστικός και παράλογος. Η κριτική του φαινομενικού χρόνου κατά τον Λεϊβνίτιο είναι όμοια προς την του χώρου.
Ο χρόνος αντιμετωπίζεται συμφώνως προς την σκέψη του Αριστοτέλη είναι γενικώς η μετάβασης, η πραγματική διάρκεια του σωματικού κόσμου. Η διάρκεια ενός σώματος δεν είναι εις τον χρόνο, αλλά, από κοινού με την διάρκεια των άλλων σωμάτων, αποτελεί τον πραγματικό χρόνο. Ο χρόνος, ως πραγματικός, είναι μια όψης της πραγματικής διάρκειας του σωματικού σύμπαντος, από την οποίαν δεν διακρίνεται.
Εις τον Καντ, ο χρόνος είναι ανάλογος προς τον χώρο. “Δεν είναι εμπειρική έννοια, προερχομένη από την εμπειρία τινός, είναι μια αναγκαία παράσταση, η οποία ίσταται εις την βάση όλων των διαισθήσεων. Δεν είναι μια έννοια, ως λέγεται, παγκόσμιος, αλλά μια καθαρή μορφή της υλικής διαισθήσεως. Ο χρόνος ουδέν άλλο είναι ει μή η μορφή της εσωτερικής αισθήσεως, ήτοι της διαισθήσεως ημών των ιδίων και της εσωτερικής μας καταστάσεως”.
Κατά τον Έγελο “οι διαστάσεις του χρόνου παρόν, μέλλον, παρελθόν, είναι το γίγνεσθαι ως τοιούτον εις την εξωτερικότητα του”.
Εις την φιλοσοφία των ημερών μας, ο χρόνος εμφανίζεται ως κατηγορία του πραγματικού.
Ο Νεοπλατωνισμός θεωρεί τον χρόνο υποκειμενικό.
Ο Πλωτίνος συνάπτει τον χρόνο όχι με τον φυσικό κόσμο, αλλά με την ψυχή και την αιωνιότητα, υποστηρίζοντας ότι ο χρόνος αποτελεί την ζωή της ψυχής και συνίσταται εις την κίνηση, δια της οποίας η ψυχή μεταβαίνει από μίαν κατάσταση ζωής εις άλλην κατάσταση ζωής.
Ο Καρτέσιος υποστηρίζει ότι ο χρόνος “ον διακρίνομεν από την γενικώς λαμβανομένην διάρκειαν και λεγομένην ότι είναι ο αριθμός της κινήσεως, ουδέν άλλο είναι ει μη ωρισμένος τις τρόπος μεθ’ ου σκεπτόμεθα την διάρκειαν ταύτην”. Διά τούτο χρόνος “έξω της αληθινής διαρκείας των πραγμάτων, ουδέν άλλο είναι ει μη εις τρόπος του σκέπτεσθαι”.
Ο Νεύτων και ο S. Clarke διατείνονται ότι ο χρόνος, ως και ο χώρος, είναι αναγκαία συνέπεια της υπάρξεως του Θεού και εν ιδίωμά του, άνευ του οποίου ο Θεός δεν θα ήτο αιώνιος.
Ο Λεϊβνίτιος διατυπώνει το παράδοξον ότι “ο Θεός θα εξαρτάται κατά τινα τρόπον εκ του χρόνου και θα έχη ανάγκην τούτου”. Επιμένει δε ότι ο χρόνος είναι “καθαρώς σχετικός είναι μία τάξις διαδοχών, η τάξις των ασταθών δυνατοτήτων, αίτινες έχουν μία συνάφειαν. Ο απόλυτος χρόνος, ο οποίος ευρίσκεται έξω των προσκαίρων πραγμάτων, είναι μηδέν”.
Ο G. Berkeley κρίνει τον απόλυτον χρόνον του Νεύτωνος και υποστηρίζει ότι “ο χρόνος είναι μηδέν όταν γίνεται αφαίρεσις από την διαδοχήν των ιδεών του νοός μας”.
Εις την αρχαία Ελληνική φιλοσοφία, ο χρόνος θεωρείται υπό πνεύμα ρεαλιστικό.
Ο Πυθαγόρης θεωρούσε τον χρόνο ως σφαίρα η οποία περιβάλλει το Παν (H. Diels, Die Frag..).
Ο Πλάτων συνάπτει την μεταβλητότητα με τον χρόνο και την αιωνιότητα με το αμετάβλητο.
Ο Αριστοτέλης αναφερόμενος εις τον χρόνο διατείνεται ότι, ο χρόνος αποτελεί μίαν όψιν της διαρκούς κινήσεως των σωμάτων, επ’ αυτού δε στηρίζεται η υποκειμενικότης του. Ο χρόνος δεν είναι η κίνησις, εφ’ όσον υπάρχουν πολλαί κινήσεις επί μέρους, ενώ ο χρόνος είναι μοναδικός.
Οι Στωϊκοί δέχονται ότι ο χρόνος είναι ασώματος, ενδιάμεσον της κινήσεως του σύμπαντος (Διογένης Λαέρτιος).
Ο Ζήνων χρησιμοποιεί τον περί ενδιαμέσου ορισμό του χρόνου και υποστηρίζει ότι “χρόνος είναι ψυχή και όρος ταχύτητος και βραδύτητος των όντων επί μέρους και συμφώνως προς αυτόν άρχονται, λήγουν και υπάρχουν τα πάντα”
Σε αυτό το γίγνεσθαι της αδιάκοπης χρονικής «ροής» ο Ηράκλειτος θα διαβλέψει μια σύνθεση της ύπαρξης και της ανυπαρξίας, που την πιστοποιούμε ως εμπειρία αδιάκοπα καινούργιων πραγματοποιήσεων: «στο ίδιο ποτάμι δεν γίνεται να μπούμε δυο φορές» – τα νερά που μας βρέχουν κάθε φορά είναι άλλα. Η «ροή» είναι κυκλική, όχι σταθερή περιοδική επανάληψη των ίδιων γεγονότων, αλλά μια αδιάκοπα επιστρεπτική ενοποίηση κάθε έκφανσης του υπάρχειν (ροή συναγωγής και διασκορπισμού, σύστασης και αφανισμού, παρουσίας και απουσίας).
Χρόνος είναι ο Κρόνος ως Ηλιος Δημιουργός, ένας Θεός, ένα Ον, που γεννάει παιδιά και τα τρώει (δημιουργεί, δημιουργεί, δημιουργεί, στο άπειρο, δημιουργίες) Η εικόνα αναπαράγει τη χρονική διαδοχή σαν πραγματικότητα προσωποποιημένη: Κάποιος «Θεός-Δημιουργός» μεταβάλλει αδιάκοπα το παρόν, σε παρελθόν, την ύπαρξη σε ανυπαρξία και τούμπαλιν ΤΑΥΤΟΧΡΟΝΑ.
Η κριτική σκέψη, που πρωτογέννησαν στην ανθρώπινη Ιστορία, οι προ-αρχαίοι Έλληνες Φιλόσοφοι, αποπροσωποποίησε τον γεννήτορα-δημιουργό: Τον χρόνο τον γεννάει η μεταβολή, η αέναη στο σύμπαν κίνηση. Ταυτίζεται ο χρόνος με την ουράνια σφαίρα στην κίνησή της, τα ουράνια σώματα είναι «όργανα χρόνου», μέτρα για να μετράμε τον χρόνο. Σε άμεση συνάρτηση με την ύλη, που είναι το δεδομένο και άναρχο υποκείμενο της κινητικής μεταβολής, είναι και ο χρόνος αγέννητος, άπειρος (δίχως πέρατα), στοιχείο αναπόσπαστο της κοσμικής ολότητας, ανερμήνευτα δεδομένο «γίγνεσθαι» συστατικό του υπάρχειν.
Η Fractal Εννοια του Χρόνου
Υπάρχει μια ιστορία σε πολλές κουλτούρες και πολιτισμούς με πολλές παραλλαγές που όμως λέει το ίδιο. Την έννοια του Fractal Χρόνου και την θεώρηση του Κβαντικού Άλματος. Δεν είναι Επιστημονική αλλά Πνευματική. Άλλωστε οι Πνευματικοί και οι Φιλόσοφοι από πάντα Ξέρουν κι αυτούς τους φιλόσοφους απλά επιβεβαιώνουν σήμερα οι επιστήμονες της σύγχρονης κοινωνίας.
Μια μέρα ένας μοναχός γυρνώντας από το δάσος που είχε πάει για να μαζέψει ξύλα, στάθηκε για να ακούσει ένα πουλί που κελαηδούσε. Μαγεύτηκε με το τραγούδι του που ήταν πάρα πολύ ωραίο και ο μοναχός στάθηκε λίγη ώρα πριν να συνεχίσει τον δρόμο του και την δουλειά του. Όταν επέστρεψε στο μοναστήρι, βρήκε νέα πρόσωπα άγνωστα σε αυτόν, άλλο μοναστήρι και άλλο χρόνο. Ακούγοντας το τραγούδι του πουλιού είχε περάσει ένας ολόκληρος αιώνας και οι φίλοι του είχαν πεθάνει. Μπαίνοντας ολοκληρωτικά σε ένα πολύ μικρό λεπτό του χρόνου είχε αγγίξει την αιωνιότητα.
Αν νομίζετε ότι η κάθε μέρα της ζωής σας έχει ακριβώς 24 ώρες, πλανάστε πλάνην οικτρά. Όπως είναι γνωστό, η διάρκεια της ημέρας αλλάζει ανά περιόδους εξ αιτίας μεταβολών στην περιστροφή της Γης, αναφέρουν νεότερες έρευνες. Νέα μελέτη «μετράει» κάθε πότε ακριβώς συμβαίνει αυτό, εντοπίζοντας μάλιστα έναν «έξτρα», άγνωστο ως τώρα παράγοντα που «παίζει» με το εικοσιτετράωρό μας και φαίνεται να συνδέεται με το ΜΑΓΝΗΤΙΚΟ πεδίο της Γης και την ηλεκτρική θεωρία του σύμπαντος.
«Λόξυγκας» στην περιστροφή της Γης
Η περιστροφή της Γης παρουσιάζει διακυμάνσεις κάθε χρόνο ή ανά δεκαετία εξαιτίας μεταβολών που σημειώνονται στην ατμόσφαιρα και στους ωκεανούς της αλλά και στο εσωτερικό της, στον μανδύα και τον πυρήνα της. Ωστόσο οι ακριβείς μεταβολές που προκαλούν οι διακυμάνσεις αυτές στη διάρκεια της ημέρας και τα «μοτίβα» που ακολουθούν δεν ήταν πλήρως γνωστά στους επιστήμονες. Μια ομάδα ερευνητών με επικεφαλής τον Ρίτσαρντ Χολμ του Πανεπιστημίου του Λίβερπουλ της Βρετανίας ανέλυσε αστρονομικά και δορυφορικά δεδομένα από το 1969 ως σήμερα με στόχο να τις καταγράψει.
Στη μελέτη τους, που δημοσιεύθηκε στην επιθεώρηση «Nature», παρουσιάζουν τη σαφέστερη «απεικόνιση» της διάρκειας του εικοσιτετραώρου μας για τα τελευταία πενήντα χρόνια. Οι ερευνητές εντόπισαν τρεις διαφορετικούς παράγοντες που προκαλούν «λόξυγκα» στην κίνηση της Γης καθώς αυτή γυρίζει γύρω από τον εαυτό της – και αυξομειώνουν σε διαφορετικό βαθμό τη διάρκεια της μέρας μας σε τρεις διαφορετικούς κύκλους.
Επιρροές από τα «σπλάχνα» της Γης
Κατ’ αρχάς κατέγραψαν λεπτομερώς μια γνωστή διακύμανση, κατά την οποία η διάρκεια της ημέρας αυξάνεται ή μειώνεται ανά περίπου μια δεκαετία κατά μερικά χιλιοστά του δευτερολέπτου για να επανέλθει μετά στα «φυσιολογικά» της επίπεδα. Η διακύμανση αυτή οφείλεται σε βραδείες μεταβολές που σημειώνονται στον πυρήνα της Γης. Ο δεύτερος κύκλος που καταγράφηκε οφείλεται επίσης σε διεργασίες που σημειώνονται στο εσωτερικό του πλανήτη, και συγκεκριμένα στους συνεχείς κλυδωνισμούς που παρατηρούνται από την αλληλεπίδραση του ρευστού πυρήνα και του στερεού μανδύα του, και ως τώρα δεν ήταν πολύ γνωστός στους ειδκούς. Όπως αποδείχθηκε, ο κύκλος αυτός διαρκεί 5,9 έτη και αλλάζει τη διάρκεια της ημέρας κατά κλάσματα του χιλιοστού του δευτερολέπτου κάθε χρόνο.
Μαγνητική αναπήδηση
Οι ερευνητές κατέγραψαν όμως και μια τρίτη κατηγορία μεταβολών, η οποία ως τώρα δεν είχε παρατηρηθεί. Είδαν ότι τρεις φορές μέσα στα τελευταία χρόνια, και συγκεκριμένα το 2003, το 2004 και το 2007, η περιστροφή του πλανήτη παρουσίασεμικρές «αναπηδήσεις». Οι αναπηδήσεις αυτές παρεμβάλλονται αλλάζοντας τις πιο μακροπρόθεσμες μεταβολές κατά ένα κλάσμα του χιλιοστού του δευτερολέπτου και διαρκούν για μερικούς μήνες προτού τα πράγματα επανέλθουν στη φυσιολογική τους κατάσταση.
Ελέγχοντας δορυφορικές δεδομένα σχετικά με το μαγνητικό πεδίο της Γης την τελευταία 20ετία οι επιστήμονες είδαν ότι ανάλογες αναπηδήσεις, οι οποίες συμπίπτουν με αυτές της περιστροφής, σημειώνονται και στο μαγνητικό πεδίο του πλανήτη. Ο κ. Χολμ υποπτεύεται ότι αυτές οι ξαφνικές μεταβολές ενδεχομένως προκαλούνται όταν ένα κομμάτι λιωμένου πυρήνα προσκολλάται προσωρινά στον μανδύα, αλλάζοντας τη γωνιακή ταχύτητα της Γης.
Χρόνος Καθρέφτης
Κατά τον Richard Feynman δεν υπάρχουν δυο αντίθετα ηλεκτρικά φορτία. Αυτό που υπάρχει είναι η μεταξύ των φορτίων αντίθετη κίνηση στο χρόνο. Τα περίφημα διαγράμματα Feynman! Ναι αλλά η βαλίτσα πάει μακριά! Τότε που το «πέταξε» το σήκωσαν οι φυσικοί σαν άλλον ένα σβώλο απ’ αυτούς που μέχρι τότε «παίζανε» Μόνο που ο R. Feynman τους πέταξε χειροβομβίδα! Ήρθε η ώρα ν’ την απασφαλίσουμε.
Ο χρόνος είναι κυριολεκτικά άλλος ένας χώρος και σαν χώρος απλά υπάρχει, δεν κινείται. Δυο φορτία –έστω δυο ηλεκτρόνια, κινούνται μεταξύ τους αντίθετα, πρέπει να λάβουμε υπ’ όψη σε ποιο χώρο τα παρατηρούμε. Στο «χώρο» χώρο ή στο «χώρο» χρόνο! Στον πρώτο «χώρο» τα βλέπουμε με ίδιο φορτίο, αλλά αν τα παρατηρούμε στο «χώρο» χρόνο τότε το ένα θα το βλέπουμε ηλεκτρόνιο και το άλλο ποζιτρόνιο!!! Μια συμμετρία ανάλογη του καθρέφτη –το δεξί γίνεται αριστερό ή αλλιώς στον άξονα των χ τα συν γίνονται πλην στο είδωλο.
Δηλαδή ο «χώρος» χρόνος είναι κ α θ ρ έ φ τ η ς!
Αυτό που υπάρχει «έξω» από τον καθρέφτη –το πραγματικό, μέσα στον καθρέφτη είναι είδωλο άυλο και όχι μόνο! Το είδωλο εντός του καθρέφτη περιέχει μονάχα την πληροφορία της μορφής του εκτός αυτού αντικειμένου και με την ολογραφία -είδωλο του καθρέφτη- ολογράμματος! Περί της ουσίας του αντικειμένου περί της δομής του, περί της συστάσεως του και τα δυο είδωλα έχουν ουδεμία πληροφορία –ουδαμώς φέρουν πλήρως!
Α: Ο καθρέφτης «περιέχει» Μόνο είδωλα!
Β: Ο χρόνος είναι καθρέφτης
Γ: Ο «χώρος» χρόνος περιέχει είδωλα -μορφικές πληροφορίες
Δ: Ο χωροχρόνος είναι μιγαδικός. Περιέχει τα αντικείμενα ΚΑΙ τα είδωλα τους!
Ε: Η μορφή· που δεν είναι η ουσία του πράγματος, φαίνεται μόνο στον καθρέφτη ως είδωλο αντικειμένου
Στ: Το είδωλο σου προσφέρει μόνο αντίληψη του αντικειμένου, όχι Κατανόηση – Επίγνωση
Ζ: Επειδή όλες οι παρατηρήσεις και μετρήσεις της φυσικής γίνονται επί/εντός του καθρέφτη χρόνου, μόνο αντίληψη έχουμε και ποτέ κατανόηση των πραγμάτων π.χ. αντιλαμβανόμαστε το ηλεκτρικό φορτίο, ΤΙ ΕΙΝΑΙ δεν κατανοούμε ακόμα. Να θυμίσω βεβαίως ότι αξιωματική θεμελιώδη έννοια της φυσικής -μητέρας των επιστημών, αποτελεί ο χρόνος!
Το ολογραφικό σύμπαν; Το τελευταίο ‘φρούτο’ της φυσικής.
Η: Έχουμε «γεννηθεί» από το ΟΛΟΝ – ΕΝ – ΠΑΝ – ΠΗΓΗ ως όντα με επιγνωστική αναπηρία; Ή μας «τροποποίησαν» κάποιοι, κάποτε, για λόγους που μόνο οι κάποιοι γνωρίζουν κι εμείς εικασίες να κάνουμε μόνο μπορούμε!
Η ΑΝΤΙΛΗΨΗ ΤΩΝ ΠΡΑΓΜΑΤΩΝ ΑΞΙΖΕΙ ΟΣΟ ΚΑΙ ΜΙΑ ΤΡΥΠΑ ΣΤΟ ΝΕΡΟ.
ΑΠΟΛΥΤΩΣ ΤΙΠΟΤΑ ΣΟΥ ΛΕΕΙ ΓΙΑ ΤΗΝ ΟΥΣΙΑ / ΦΥΣΗ / ΠΟΙΟΝ ΤΩΝ ΠΡΑΓΜΑΤΩΝ!
Αγκάλιασε, χαστούκισε, φίλησε, φτύσε το είδωλο σου στο καθρέφτη! Όχι το γυαλί! Χειρούργησε το ανοίγοντας του τομή, επιδιόρθωσε μια βλάβη όποιου οργάνου του, σκούπισε τα αίματα, ράψε το (μη ξεχάσεις και το φακελάκι)! Μπορείς να τα κάνεις αυτά στο είδωλο σου; Όχι; Γιατί όχι;
Διότι το είδωλο είναι και άυλο και σε άλλο κυριολεκτικά χώρο, αυτόν μέσα στον καθρέφτη! Ενώ εσύ αυτή καθαυτή η οντότητα έχεις ύλη και χώρο – όχι χρόνο. Και με την λέξη ύλη να εννοούμε πλέον το ποιόν το φέρον και ΔΕΝ ΙΣΧΥΕΙ η αντιμεταθετική ιδιότητα! Τροποποίηση σε σένα επιφέρει τροποποίηση στο είδωλο σου!! όχι το αντίθετο !!
Πως, τίνι τρόπω απαλλάσσεσαι από τον καθρέφτη; Μήπως η συνείδηση μας είναι εγκλωβισμένη στο καθρέφτη – «χώρο» του χρόνου, ώστε να έχει μόνο αντίληψη της φέρουσας οντότητας της και όχι επίγνωση; Πατάμε με το ένα πόδι σ’ αυτό που όντως είμαστε και με το άλλο πόδι στο είδωλο-εικονική πραγματικότητα.
Μόνοι μας το πάθαμε; Μας το πάθανε; Δεν ξέρω ! Από την πιο στυγνή υλιστική θεώρηση των πραγμάτων ως την πιο αποκρυφιστική και μεταφυσική, υπάρχει τέτοια ποικιλία, που δε φτάνει μια ζωή να διαλέγεις!
Η θεωρεία της σχετικότητας είναι μια σαχλαμάρα. Η δε κβαντική, θ’ αποδειχθεί ότι είναι μια απλή περιγραφική θεωρεία, μη δυνάμενη να προσδιορίσει ή εξηγήσει την ύλη. Το «γιατί αυτό έτσι». π.χ γιατί το ηλεκτρόνιο είναι σταθερό, γιατί έχει τόση μάζα, γιατί σπιν 1/2. Σχέσεις βρήκε η κβαντοφυσική. Αντικατέστησε την αιτιοκρατία με την πιθανοκρατία.
Το Χάος όμως, το απρόβλεπτο χάος είναι αιτιοκρατικό αυστηρά.
Όσον αφορά το χρόνο. Ούτε ο χρόνος, ούτε η μάζα, ούτε το φορτίο, ούτε το πεδίο γνωρίζουμε τι είναι. Όχι, δεν μας τα λέει καλά η κβαντοφυσική! Παρατηρώντας την φύση, ένα είναι το απόφθεγμα –του Θαλή. «Ισχυρότατον η ανάγκη, κρατεί γαρ πάντων». Κι εδώ κόλλησε το μούτρο μας στο τείχος του αδιεξόδου. Παραδεχθήκαμε κι αποδεχθήκαμε την υποταγή μας στην Ανάγκη.
Κι ενός κακού -της υποταγής, μύρια έπονται.
Οι ερειπιώνες που κτίζει επιμελώς ο άνθρωπος από τότε που υποτάχθηκε στην Α ν ά γ κ η, ακόμα κι αν κάποιοι άλλοι τον υπέταξαν, θα πρεπε να επιλέξει τον θάνατο, δηλαδή την ανυπαρξία παρά την σκλαβιά της υποταγής, δηλαδή το υπό-άρχειν! Ψηφίζω υπέρ των αρχών, αλλά τίνος οι αρχές; Θέσπιση αρχών εξ υμών ερήμην ημών; Ένας από τους λόγους που τα φράκταλ είχαν τόση απήχηση είναι η ευκολία και η ομορφιά των παραστάσεων τους. Όμως:
Η Μορφή ανήκει στα Φράκταλ.
Η Δομή ανήκει στη λωρίδα του Μέμπιους.
Στην Σχετικότητα και την Κβαντοφυσική, οι θεωρίες πεδίου και αιθέρα δεν λαμβάνουν υπ’ όψιν τους τις θαυμαστές ιδιότητες της, άμεσα συγγενείς με τους στροβίλους των πεδίων και του αιθέρα. Περί οξύνειας και διανοίας των λαμπρών επιστημόνων σας μεταφέρω τούτο μόνο. Οι γαλαξίες – λένε οι αστροφυσικοί – περιστρέφονται ως συμπαγείς δίσκοι, σαν περιστρεφόμενα ταψιά. «Το μετρήσαμε» είναι το επιχείρημα τους.
Ξέρετε πόσοι εξωγήινοι πέθαναν γελώντας όταν το άκουσαν;
Σχεδόν όλοι τους, γι’ αυτό και δεν τους εντοπίσαμε ακόμα κι ούτε πρόκειται!
At the Mars Desert Research Station, every crew member is realising scientific experiments. Those experiments are prepared, sometimes in collaboration with companies and/or researchers, during the whole year preceding the mission.
Are you a company or an academic interested in using our user case on Mars ? Do you want to work together with us in order to realize a scientific experience ? Let us know !
The Mars Desert Research Station (MDRS), owned and operated by the Mars Society, is a space analog facility in Utah that supports Earth-based research in pursuit of the technology, operations, and science required for human space exploration. We host an eight month field season for professional scientists and engineers as well as college students of all levels, in training for human operations specifically on Mars. The relative isolation of the facility allows for rigorous field studies as well as human factors research. Most crews carry out their mission under the constraints of a simulated Mars mission. Most missions are 2-3 weeks in duration, although we have supported longer missions as well. The advantage of MDRS over most facilities for simulated space missions is that the campus is surrounded by a landscape that is an actual geologic Mars analog, which offers opportunities for rigorous field studies as they would be conducted during an actual space mission.
Campus
The MDRS campus includes six structures. The habitat (Hab) is a two story 8 meter in diameter cylindrical building constructed in 2001. It can house seven crewmembers at one time. The structure has been undergoing a refurbishment over the last few years. The lower deck houses the EVA prep room with the spacesuit simulators, an exterior airlock, a shower room, toilet room and a rear airlock leading to tunnels, which access other structures. The upper deck houses the living quarters, which include a common work/living area, fully operational kitchen and seven staterooms with bunks. Six of the staterooms are on the main floor, a seventh is housed in the loft.
There are two observatories on campus. The Robotic Observatory houses a 14″ Celestron Schmidt-Cassegrain telescope on a CGE pro equatorial mount. Attached is a 4″ refractor, which is used as a guide scope. Either telescope can utilize a wide array of cameras for astronomical imaging. The telescope is housed in a 7.5 foot automated dome that can be controlled on site or from the habitat module. The Musk Observatory, formerly the only observatory on campus, has been converted into a solar observatory for use by crews.
The GreenHab was fully funded by donations. It is a 12” by 24” foot structure, housing both conventional and aquaponic growing systems, in addition to space devoted to crop research studies. It is climate controlled though a propane heater and swamp cooler, and has broad spectrum grow lights of additional light during the winter months.
The Science Dome is a 7-meter in diameter geodesic dome that contains our solar system’s control center and is a functional microbiological and geological laboratory.
The RAMM (Repair and Maintenance Module) is our newest building, and will be on site before the beginning of 2018. A refitted Chinook helicopter, this spectacular addition to the campus can house an ATV/rover for repairs and will be used for engineering research.
All of the structures with the exception of the Robotic Observatory are linked with the Hab via above ground tunnels to allow participants to utilize these buildings while remaining in simulation. The campus is powered by a 15 kW solar system that feeds a 12 kW battery bank that provides power to everything. A 12 kW generator autostarts when the campus uses more power than the solar can provide in the winter months.
Crews occupying the station are fully supported. The station is operational with all systems functional during their stay. Shelf-stable foods such as those used on space missions are supplied for each crew. Additional support equipment includes five All Terrain Vehicles and four all electric two person Polaris Rangers for field transportation, as well as a 4 wheel drive SUV. The director lives on site and manages the station and operations. In addition, there are a host of volunteer teams supporting all aspects of the work that is done at the station, including peer review of all research proposals and supporting crews via offsite Mission Support.
MDRS began operations in 2001 as a fully volunteer enterprise. Over 1,000 people have participated as crew and many are now involved in other analog studies at different places around the world. Thousands of other people have supported our mission in many other ways, all of them dedicated to the idea of sending humans to Mars.
B)Our Experiments
1)Dust Understanding for Solar Technology Yield (DUSTY)
Space is a dangerous and relentless, throwing challenges to everybody who dares venture into the unknown. Collecting and understanding data from an alien world is key to survival, that is why my experiment is going to be about the study of the danger of dust from Martian storms. These storms are not very well understood and the dust they pick up can be hazardous for the vital equipment such as the solar panels. I will use two weather stations that will track luminosity, air pressure, wind speed and temperature for two weeks and use my mapping skills to figure out if the environment around the MDRS is suitable for sensitive equipment or not. One of the weather stations will be stationary during the two weeks and the other will be mobile, moved each day to a new location to try and gauge the exposition to dust and wind.
(ΣΕ ΣΥΝΕΧΕΙΑ ΣΕΙΡΑΣ ΑΡΘΡΩΝ ΜΕ ΤΕΛΕΥΤΑΙΟΝ ΑΠΟ 26/02/2007)
Το Φεβρουάριο του 2003 ο δορυφόρος WMAP (διάδοχος του COBE που φτιάχτηκε για να μετρήσει την Κοσμική Ακτινοβολία Υποβάθρου με 35 φορές καλύτερη ανάλυση) έφτιαξε μια ακόμα πιο λεπτομερή εικόνα της Κοσμικής Ακτινοβολίας Υποβάθρου (CMB), την ακτινοβολία που εκπέμφθηκε από το σύμπαν όταν είχαν περάσει 380.000 χρόνια από το Big Bang. Η ακτινοβολία αυτή που θεωρείται το αρχαιότερο φως στον Κόσμο, διέρρευσε από το νεογέννητο σύμπαν όταν αυτό ήταν ακόμα μια πυρακτωμένη σφαίρα πλάσματος.
Ένας πλήρης Ουράνιος χάρτης του παλαιότερου φωτός στο Σύμπαν. Τα χρώματα δείχνουν «τη θερμότερη περιοχή» (κόκκινο) και την «πιο ψυχρή» (μπλε σημεία). Η ωοειδής μορφή είναι μια προβολή για να παρουσιάσει ολόκληρο τον Ουρανό.
Πολύ πριν να υπάρξουν αστέρια και γαλαξίες, το σύμπαν αποτελούνταν από ένα καυτό, λαμπρό πλάσμα που αναταρασσόταν κάτω από τις ανταγωνιστικές επιδράσεις της βαρύτητας και της ακτινοβολίας. Τα καυτά σημεία στην Κοσμική Ακτινοβολία Υποβάθρου είναι οι εικόνες του συμπιεσμένου, πυκνού πλάσματος σε ένα σύμπαν που συνεχώς ψύχεται, ενώ τα ψυχρά σημεία του χάρτη είναι η υπογραφή των απόκρυφων, εσωτερικών, περιοχών του αερίου.
Ακριβώς όπως ο τόνος ενός κουδουνιού εξαρτάται από τη μορφή του και το υλικό από το οποίο αποτελείται, έτσι συμβαίνει και με τον ‘ήχο’ του αρχικού σύμπαντος — η αναλογία των υλικών του και τα μεγέθη των καυτών και ψυχρών σημείων στην CMB — που εξαρτάται από τη σύνθεση του σύμπαντος και τη μορφή του. Ο δορυφόρος WMAP επέτρεψε τελικά στους επιστήμονες να ακούσουν αυτή την ουράνια μουσική και να υπολογίσουν από τι αποτελείται ο Κόσμος μας.
Αναλύοντας τα δεδομένα του WMAP, οι ερευνητές συμπέραναν ότι το σύμπαν αποτελείται μόνο 4% από τη συνηθισμένη ύλη. Το 23% είναι η αόρατη σκοτεινή ύλη, που οι αστροφυσικοί θεωρούν ότι είναι φτιαγμένη, μέχρι σήμερα, από άγνωστα σωματίδια. Το υπόλοιπο, 73%, είναι η περίφημη σκοτεινή ενέργεια.
Το WMAP ανακάλυψε, επίσης, και άλλες βασικές ιδιότητες του Σύμπαντος, συμπεριλαμβανομένης της ηλικίας του (13,7 δισεκατομμύρια έτη), του ρυθμού διαστολής και της πυκνότητας.
Μια από τις μεγαλύτερες εκπλήξεις που αποκαλύφθηκαν από τα στοιχεία του WMAP, είναι ότι η πρώτη γενεά των άστρων άρχισε να λάμπει στον Κόσμο μόνο 200 εκατομμύρια χρόνια μετά από το Μεγάλη Έκρηξη, πολύ νωρίτερα από όσο ανέμεναν πολλοί επιστήμονες. Για να υπολογίσει ακριβώς πότε άρχισε ο σχηματισμός των άστρων, η ομάδα του WMAP δεν είδε κατευθείαν το φως των πρώτων άστρων αλλά μέτρησε τις απίστευτα λεπτές παραλλαγές στην πόλωση της μικροκυματικής ακτινοβολίας υποβάθρου.
Ο ρυθμός διαστολής του σύμπαντος (η σταθερά Hubble) βρέθηκε ότι είναι: Ho= 71 km/sec/Mpc (μ’ ένα περιθώριο λάθους περίπου 5%). Για να ταιριάξει δε η θεωρία με τα δεδομένα δεχόμαστε την παντοτινή διαστολή του σύμπαντος.
Το σύμπαν τελικά, σύμφωνα με τα δεδομένα του WMAP, είναι επίπεδο ενώ η βαρυονική πυκνότητα είναι = 0.044 ± 0.004, η πυκνότητα της σκοτεινής ύλης = 0.23 ± 0.04, και η εναπομένουσα πυκνότητα 0.73 ± 0.04 περιγράφεται σαν η «σκοτεινή ενέργεια του κενού».
Η ποσότητα της σκοτεινής ύλης και της ενέργειας στο Σύμπαν φαίνεται ότι παίζει κρίσιμο ρόλο στον καθορισμό της γεωμετρίας του Χώρου. Γιατί:
1. Αν η συνολική πυκνότητα της ύλης και της ενέργειας στο Σύμπαν ρ < ρο , (όπου ρο η κρίσιμος πυκνότητα) τότε ο χώρος είναι ανοικτός και με αρνητική καμπυλότητα όπως η επιφάνεια ενός σαμαριού.
2. Αν η πυκνότητα είναι ρ > ρο (όπου ρο η κρίσιμος πυκνότητα) μεγαλύτερη από την κρίσιμη πυκνότητα, τότε ο χώρος είναι κλειστός και θετικά καμπυλωμένος όπως η επιφάνεια μιας σφαίρας. Στην τελευταία περίπτωση, οι τροχιές του φωτός διίστανται και τελικά ενώνονται πάλι σε ένα σημείο.
3. Τέλος, αν η πυκνότητα είναι ακριβώς ίση με την κρίσιμη πυκνότητα ρ = ρο, τότε ο χώρος είναι επίπεδος όπως ένα φύλλο χαρτί. Αυτό το σενάριο επιβεβαίωσε και ο δορυφόρος WMAP.
Η θεωρία του πληθωρισμού, η προέκταση της θεωρίας του Big Bang, προβλέπει ότι η πυκνότητα του σύμπαντος πρέπει να είναι πολύ κοντά στην κρίσιμη πυκνότητα, παράγοντας έτσι ένα επίπεδο σύμπαν.
Η εξέλιξη και το σχήμα του σύμπαντος
Αν λύσουμε τις εξισώσεις πεδίου του Αϊνστάιν, με τη βοήθεια και της μετρικής του διαστελλόμενου χώρου, βρίσκουμε ότι η μελλοντική εξέλιξη του Σύμπαντος εξαρτάται από το συνολικό ποσό της ύλης και της ενέργειας που περιέχει. Στην πιο απλή μορφή αυτών των λύσεων, (χωρίς να υπολογίσουμε την κοσμολογική σταθερά Λ), υπάρχουν οι εξής δυνατές περιπτώσεις μεταξύ ύλης και γεωμετρίας:
1. Αν το σύμπαν περιέχει μικρή ποσότητα ύλης τότε θα διαστέλλεται συνεχώς γιατί η βαρύτητα δεν μπορεί να το συγκρατήσει (είναι η περίπτωση του ανοικτού σύμπαντος). Η δε γεωμετρία που το διέπει είναι υπερβολική (στις δύο διαστάσεις ένα ανάλογο σχήμα είναι αυτό μιας σέλας αλόγου).
2. Αν περιέχει μεγάλη ποσότητα ύλης τότε το σύμπαν θα αρχίσει να συστέλλεται μετά από κάποιο χρονικό διάστημα γιατί η βαρύτητα θα αρχίσει να γίνεται τότε σημαντική (περίπτωση κλειστού σύμπαντος).Η δε γεωμετρία που το διέπει είναι σφαιρική.
3. Αν περιέχει ένα συγκεκριμένο κρίσιμο ποσό ύλης (το σύνορο μεταξύ των δύο παραπάνω περιπτώσεων), τότε η γεωμετρία είναι η γνωστή μας Ευκλείδια (επίπεδο σύμπαν).
Με την προσθήκη της κοσμολογικής σταθεράς Λ αυτή η αντιστοιχία μεταξύ ύλης και γεωμετρίας παύει αν ισχύει και είναι δυνατόν το Σύμπαν να περιέχει μικρό ποσό κανονικής ύλης αλλά η γεωμετρία που το διέπει να είναι η Ευκλείδια. Αυτό μπορεί να συμβεί επειδή η Κοσμολογική Σταθερά Λ λειτουργεί σαν εν δυνάμει ύλη (σκοτεινή ενέργεια του κενού), η οποία συμπληρώνει την απαραίτητη ποσότητα της κανονικής ύλης (βαρυονικής και σκοτεινής ύλης) ώστε το Σύμπαν να είναι επίπεδο.
Έχει λοιπόν βρεθεί ότι το Σύμπαν διαστέλλεται σήμερα με ρυθμό πολύ κοντά στην κρίσιμη τιμή, γεγονός που χρειάζεται εξήγηση μιας και γνωρίζουμε από τις λύσεις των εξισώσεων του Αϊνστάιν, ότι εάν το Σύμπαν δεν ξεκινούσε την διαστολή του με ακριβώς αυτό τον ρυθμό, τότε με την πάροδο του χρόνου θα απέκλινε όλο και περισσότερο από αυτόν και σήμερα θα μετρούσαμε εντελώς διαφορετικό ρυθμό διαστολής.
Η παρουσία των κοσμικών δομών (αστέρων, γαλαξιών και σμήνη γαλαξιών), δείχνει ότι ο ρυθμός διαστολής είναι ακριβώς αυτός που χρειάζεται για να δημιουργηθούν.
Γιατί αν το Σύμπαν διαστελλόταν με ρυθμό πολύ μεγαλύτερο της κρίσιμης τιμής τότε η βαρύτητα που ασκείται συνολικά στο Σύμπαν, από την εμπεριεχόμενη εντός αυτού ύλης και ενέργειας, δεν θα ήταν σε θέση να αντιστρέψει τη διαστολή σε συστολή ούτε στις περιοχές υψηλής πυκνότητας. Κι έτσι δεν θα είχαν γεννηθεί τα άστρα, στον πυρήνα των οποίων δημιουργούνται τα συστατικά στοιχεία από τα οποία είναι φτιαγμένα τα έμβια όντα (οξυγόνο, υδρογόνο, άνθρακας κλπ) και η εξέλιξη των οποίων τελικά τροφοδοτεί, με αυτά τα στοιχεία, το Σύμπαν.
Επίσης, εάν το Σύμπαν διαστελλόταν με ρυθμό σημαντικά βραδύτερο της κρίσιμης τιμής τότε πάλι πριν προλάβουν να δημιουργηθούν τα άστρα, το Σύμπαν θα είχε ξανασυσταλλεί σε μία υπέρθερμη θάλασσα ακτινοβολίας. Επομένως, το γεγονός της ύπαρξης των κοσμικών δομών προϋποθέτει ότι το Σύμπαν διαστέλλεται περίπου με τον ρυθμό που μετράμε.
In a post-flight analysis of the Artemis 1 uncrewed mission, NASA has identified more than 100 locations where ablative thermal protective material from the Artemis 1 Orion heat shield chipped away unexpectedly during reentry into Earth’s atmosphere.
In classic “wait a minute” style, a NASA Office of Inspector General (OIG) report has been issued – “NASA’s Readiness for the Artemis II Crewed Mission to Lunar Orbit” – calling attention to this issue and others before sending off a human crew to circle the Moon.
Image credit: NASA OIG
Root cause
To ensure the safety of the crewed Artemis II mission, the newly-issued OIG report recommends the Associate Administrator for Exploration Systems Development Mission Directorate:
“Ensure the root cause of Orion heat shield char liberation is well understood prior to launch of the Artemis II mission.
Conduct analysis of Orion separation bolts using updated models that account for char loss, design modifications, and operational changes to Orion prior to launch of the Artemis II mission.”
The report by the NASA OIG also notes that “human space flight by its very nature is inherently risky, and the Artemis campaign is no exception. We urge NASA leadership to continue balancing the achievement of its mission objectives and schedule with prioritizing the safety of its astronauts and to take the time needed to avoid any undue risk.”
Image credit: NASA OIG
Taking the heat
In earlier reporting, here’s my take on the situation, as posted on Space.com:
“NASA still investigating Orion heat shield issues from Artemis 1 moon mission” at:
For more information on the new IG report, take a look at Brett Tingley’s new story at Space.com – “NASA inspector general finds Orion heat shield issues ‘pose significant risks’ to Artemis 2 crew safety” at:
Also read this story by Eric Berger, senior space editor at Ars Technica titled “NASA says Artemis II report by its inspector general is unhelpful and redundant” at:
Orion heat shield features ablative material, called Avcoat. Image credit: Lockheed Martin
High-speed return from lunar distance, the thermal protection system of Orion’s crew module must endure blistering temperatures to keep crew members safe. Measuring 16.5 feet in diameter, Orion’s heat shield is the largest of its kind developed for missions carrying astronauts. Image credit: NASA
Interview: Peter Beck, Rocket Lab Leader – Balancing Entrepreneurial Vision and Engineering Realism
Extremely busy with an eye on the future.
That’s a short and sweet assessment of Peter Beck, Rocket Lab’s founder and CEO. In the pantheon of private space groups, Rocket Lab is a roaring success and Beck wants to keep it that way.
Rocket Lab Electron launcher on New Zealand LC-1 launch pad. Image credit: Kieran Fanning/Rocket Lab
Ask Peter Beck to weigh the firm’s past and where it’s headed. His response: “We joke that a Rocket Lab year is like a dog year. One Rocket Lab year feels like five.”
For Beck’s look at today and what’s ahead for his company, go to my new Space.com story — Building rockets and looking for life on Venus: Q&A with Rocket Lab’s Peter Beck – at:
Οι άνθρωποι έχουμε εμμονή με τον τροχό και προφανώς δεν μας φθάνει να υπάρχουν ροδιές σε επιφάνειες της Γης. Θέλουμε να βλέπουμε ροδιές και σε άλλους πλανήτες και η NASA έχει φροντίσει γι΄αυτό -και ας μην είναι ο σκοπός της να γεμίσουμε ροδιές τον πλανήτη Άρη.
Στο πλαίσιο εξερέυνησης του Κόκκινου Πλανήτη, η NASA έχει κατασκευάσει και στείλει στην επιφάνεια του Άρη πέντε τροχοφόρα οχήματα (ονομάζονται rover) και αποφασίσαμε να τους κάνουμε ένα μικρό αφιέρωμα. Οι πέντε εξερευνητές με ρόδες είναι οι: Sojourner, Opportunity και Spirit (είναι δίδυμα), Curiosity και Perseverance.
Sojourner
Το 1997, οι επιστήμονες της NASA έκαναν κάτι εκπληκτικό. Για πρώτη φορά χρησιμοποίησαν ένα μικρό ρομπότ με ρόδες για να μελετήσουν την επιφάνεια του Άρη. Αυτός ο ρομποτικός εξερευνητής, ονομάστηκε Sojourner. Είχε το μέγεθος ενός φούρνου μικροκυμάτων ενώ το βάρος του ήταν μόλις 10, 4 κιλά. Προφανώς δεν ήταν ταχύ με μέγιστη ταχύτητα τα 0,03 km/h (δηλαδή 30 μέτρα την ώρα) και σίγουρα δεν του έκοβαν χιλιόμετρα τα μόλις δύο επιστημονικά όργανα που έφερε. Είχε τρόχους μόλις 5,1 ιντσών.
Το rover εξερεύνησε μια περιοχή του Άρη κοντά στο σημείο προσεδάφισής του που ονομάζεται Ares Vallis. Οι επιστήμονες ενδιαφέρθηκαν για την περιοχή αυτή επειδή έμοιαζε με την περιοχή μιας αρχαίας πλημμύρας. Υπέθεσαν ότι τα ορμητικά νερά μιας πλημμύρας θα είχαν συγκεντρώσει πολλούς βράχους και χώμα σε ένα μέρος. Αυτό σημαίνει ότι το ρόβερ θα μπορούσε να μελετήσει πολλούς διαφορετικούς τύπους πετρωμάτων χωρίς να ταξιδέψει πολύ μακριά.
Δοκιμή του νέου τετράτροχου σεληνιακού rover στην Αίτνα
Στους μηχανικούς άρεσε επίσης η περιοχή επειδή φαινόταν σαν ένα επίπεδο, ασφαλές μέρος για να προσγειωθεί το Sojourner. Καθώς το Sojourner έκανε μικρές αποστάσεις, χρησιμοποίησε την κάμερά του για να τραβήξει φωτογραφίες του αρειανού τοπίου. Έστειλε πίσω περισσότερες από 550 φωτογραφίες του Κόκκινου Πλανήτη. Το ρόβερ χρησιμοποίησε όργανα για να μελετήσει από τι ήταν φτιαγμένα τα αρειανά πετρώματα και το χώμα.
Spirit και Opportunity
Opportunity
Μετά την επιτυχία του Sojourner, η NASA θέλησε να στείλει περισσότερα οχήματα για να μάθει τι γίνεται στον Άρη. Έτσι, το 2003, έστειλε δύο ρόβερ στον Κόκκινο Πλανήτη. Τα ρόβερ ονομάστηκαν Spirit και Opportunity. Μαζί αποτελούσαν μέρος της αποστολής Mars Exploration Rover.
Το Spirit και το Opportunity κατασκευάστηκαν ως δίδυμα. Και τα δύο έφεραν τα ίδια πέντε επιστημονικά όργανα. Το καθένα είχε περίπου το μέγεθος ενός αμαξιδίου του γκολφ. Τώρα το βάρος είχε αυξηθεί και ήταν περίπου 170 κιλά το καθένα ενώ ήταν και πιο γρήγορα. Η τελική τους του έφθανε τα 0,16 km/h (160 μέτρα την ώρα). Οι τροχοί τους πλέον έφθαναν τις 9,8 ίντσες, δηλαδή είχαν διάμετρο όσο μια μπάλα μπάσκετ.
Μια φωτό του Spirit που φαίνονται ο ρομποτικός βραχίονας και δύο τροχοί του
Το Spirit προσγειώθηκε σε μια περιοχή που ονομάζεται κρατήρας Gusev. Οι επιστήμονες θέλησαν να εξερευνήσουν τον κρατήρα επειδή πίστευαν ότι θα μπορούσε να περιέχει νερό πριν από πολύ καιρό. Από τις εικόνες που τράβηξαν οι δορυφόροι, οι επιστήμονες πίστευαν ότι φαινόταν ότι στον κρατήρα Gusev κατέληγαν πολλά μεγάλα ποτάμια.
Το Opportunity προσεδαφίστηκε στην άλλη πλευρά του Άρη σε μια περιοχή που ονομάζεται Meridiani Planum. Αυτή η περιοχή ήταν καλή επειδή ήταν ένα επίπεδο, ασφαλές σημείο για να προσγειωθεί το ρόβερ. Επίσης, μελέτες με έναν δορυφόρο γύρω από τον Άρη έδειξαν ότι μπορεί να περιέχει ένα ορυκτό που ονομάζεται γκρίζος αιματίτης. Στη Γη, ο γκρίζος αιματίτης συναντάται συχνά παρουσία νερού.
Στο ταξίδι του, το Spirit τράβηξε πολλές φωτογραφίες του Άρη με την κάμερά του. Ήταν οι πρώτες έγχρωμες φωτογραφίες που τραβήχτηκαν από ρόβερ σε άλλο πλανήτη. Το Spirit βρήκε επίσης αρκετά σημάδια νερού του παρελθόντος και ενδείξεις γεωθερμικής ή ηφαιστειακής δραστηριότητας. Εξερεύνησε τοποθεσίες που μπορεί να ήταν θερμές πηγές πριν από εκατομμύρια χρόνια.
Το Opportunity τράβηξε επίσης πολλές έγχρωμες φωτογραφίες του αρειανού τοπίου. Βρήκε επίσης ενδείξεις νερού. Το Opportunity μελέτησε στρώματα ορυκτών στο πέτρωμα κοντά στο σημείο προσεδάφισής του. Τα στοιχεία που συνέλεξε έδειξαν ότι η θέση προσεδάφισης του ήταν κάποτε η ακτογραμμή μιας αλμυρής θάλασσας.
Curiosity
Selfie του Curiosity στον πλανήτη Άρη
Τρομερό εργαλείο. Προσεδαφίστηκε στον Άρη τον Αύγουστο του 2012 και τότε όσοι αγαπάμε να βλεπουμε ίχνη από ρόδες σε άλλους πλανήτες κάναme πάρτι. Έφθανε τα 900 κιλά, είχε πάνω του 10 επιστημονικά όργανα ενώ η τελική του ταχύτητα έφθανε τα 0,14 km/h (δηλαδή κάλυπτε 140 μέτρα την ώρα). Ναι, ήταν πιο αργό από τα δίδυμα αλλά ήταν πολύ πιο βαρύ ενώ οι τροχοί του ήταν πλέον 20 ιντσών, δηλαδή όσο και σε ένα μεγάλο SUV. Το μέγεθος του πάντως ήταν όσο ένα μικρό SUV και είναι το μεγαλύτερο όχημα που έχουμε στείλει στον Άρη. Πάντως ο Musk είναι ικανός να στείλει κάνα Model Y για να πάρει τα πρωτεία της NASA.
Γιατί πήγε; ΟΚ, τα δίδυμα ανακάλυψαν ότι υπήρχε νερό και τώρα το Curiosity έπρεπε να ψάξει για ενδείξεις ζωής, πολλά πολλά χρόνια πριν προφανώς -μην σας τρομάξουμε κιόλας όπως η ταινία Life. Το Curiosity προσεδαφίστηκε στον κρατήρα Gale. Αυτός ο κρατήρας είναι ιδιαίτερος επειδή έχει ένα ψηλό βουνό στη μέση. Το βουνό έχει πολλά στρώματα βράχων. Κάθε στρώμα αποτελείται από διαφορετικά ορυκτά από διαφορετικές χρονικές περιόδους. Αυτά τα ορυκτά θα μπορούσαν να πουν στους επιστήμονες για την ιστορία του νερού στον Άρη.
Το ρόβερ χρησιμοποιεί πολλά επιστημονικά όργανα για να μελετήσει τα πετρώματα στον κρατήρα Gale. Το Curiosity χρησιμοποίησε το τρυπάνι του για να ανοίξει μια τρύπα σε έναν βράχο που κάποτε ήταν λάσπη στον πυθμένα μιας λίμνης. Ένα από τα άλλα όργανά του μελέτησε τη σκόνη που τρυπήθηκε από τον βράχο. Αυτές οι πληροφορίες βοήθησαν τους επιστήμονες να μάθουν ότι ο κρατήρας Γκέιλ είχε συστατικά που θα χρειαζόταν η αρχαία ζωή για να επιβιώσει.
Οι επιστήμονες έστειλαν το Curiosity στον Άρη για να μετρήσει πολλά άλλα πράγματα, μεταξύ των οποίων και την ακτινοβολία. Η ακτινοβολία είναι ένα είδος ενέργειας που μπορεί να προέρχεται από τον ήλιο. Ταξιδεύει σε κύματα υψηλής ενέργειας που μπορεί να είναι επιβλαβή για τα έμβια όντα. Το Curiosity διαπίστωσε ότι ο Άρης έχει υψηλά, επικίνδυνα επίπεδα ακτινοβολίας. Η NASA θα χρησιμοποιήσει τα δεδομένα ακτινοβολίας του Curiosity για να σχεδιάσει αποστολές που θα είναι ασφαλέστερες για τους ανθρώπινους εξερευνητές.
Το Curiosity έφερε μαζί του στον Κόκκινο Πλανήτη 17 κάμερες – περισσότερες από οποιοδήποτε άλλο ρόβερ. Χρησιμοποιεί ορισμένες από τις κάμερες του για να τραβήξει φωτογραφίες από το ταξίδι του. Οι κάμερες λειτουργούν επίσης ως μάτια του Curiosity, βοηθώντας το να εντοπίζει και να μένει μακριά από κινδύνους.
Μία από τις κάμερες του Curiosity -στην άκρη του ρομποτικού βραχίονα μήκους 2,5 μέτρων- λειτουργεί ακόμη και σαν ένα είδος “selfie stick”. Μπορεί να κρατήσει την κάμερα δύο μέτρα μακριά και κάπως έτσι μας στέλνει selfie. Πολύ φασαίος το Curiosity.
Perseverance
Το πιο φρέσκο rover της NASA στον πλανήτη Άρη. Ακόμα πιο βαρύ από το Curiosity, σχεδόν 1.025 κιλά αλλά με την την ίδια τελική ταχύτητα. Φέρει 7 επιστημονικά όργανα αλλά με άλλη εστίαση. Το Perceverance πήγε στον Άρη στην ουσία για να μελετήσει αν μπορούμε να πάμε και εμείς. Επίσης πήγε μαζί με ένα ελικοπτέρακι drone. Πολύ φάση.
Το νέο ρόβερ θα πειραματιστεί με έναν φυσικό πόρο που θα ήταν χρήσιμος για τον σχεδιασμό μιας ανθρώπινης αποστολής στον Άρη.
Απεικόνιση της προσεδάφισης του Perseverance
Η ατμόσφαιρα του Άρη αποτελείται κυρίως από διοξείδιο του άνθρακα. Αλλά πολλά έμβια όντα (συμπεριλαμβανομένων των ανθρώπων) χρειάζονται οξυγόνο για να αναπνεύσουν. Αν ένας άνθρωπος πήγαινε στον Άρη, θα έπρεπε να φέρει μαζί του πολύ οξυγόνο. Ωστόσο, δεν υπάρχει πολύς χώρος στο διαστημόπλοιο για να μεταφέρει υγρό οξυγόνο.
Το ρόβερ θα δοκιμάσει μια μέθοδο για τη λήψη οξυγόνου από τον αέρα της αρειανής ατμόσφαιρας. Αυτό θα βοηθήσει τη NASA να σχεδιάσει τα καλύτερα σχέδια για την αποστολή αστροναυτών για να εξερευνήσουν τον Άρη μια μέρα.
“The secret of happiness is freedom. The secret of freedom is courage.” ΘΟΥΚΙΔΙΔΗΣ
As long as man continues to be the ruthless destroyer of lower living beings he will never know health or peace. For as long as men massacre animals, they will kill each other.
Pythagoras













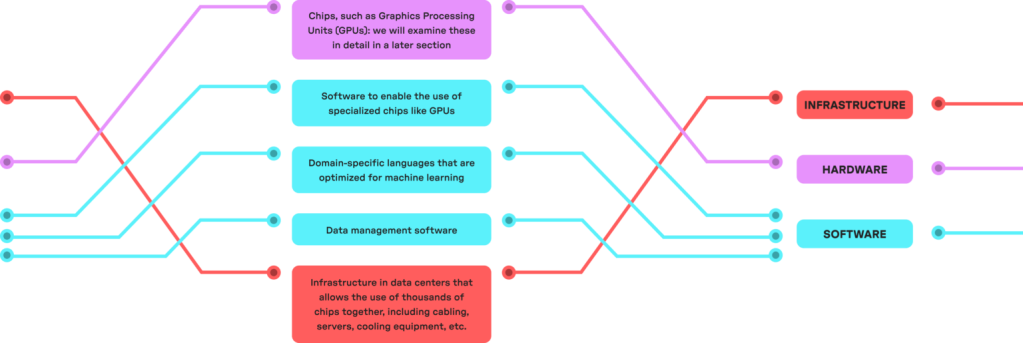






























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
You must be logged in to post a comment.